西瓜书阅读笔记——第4章-决策树
西瓜书阅读笔记——第4章-决策树
算法原理
决策树是基于树结构对问题进行决策或判定的过程。
决策过程中提出的判定问题(内部节点)是对某个属性的“测试”,每个测试的结果可以导出最终结论(叶节点)或导出进一步判定问题(下一层内部节点,其考虑范围是在上次决策结果的限定范围之内)。
核心是选取划分条件(划分属性)。
最终目的样本划分越“纯”越好。
常见决策树算法
ID3决策树
信息熵
信息熵可以度量随机变量X的不确定性,信息熵越大越不确定,可转换到度量样本集合纯度,信息熵越小样本集合的纯度越高。
样本集合\(D\)中第\(k\)类样本所占比例为\(p_k(k=1,2,3...,N)\),则\(D\)的信息熵定义为: \[
Ent(D)=-\sum\limits_{k=1}^{N}p_k * log2(p_k)
\]
当样本集合中各个类别所占比例相同时(\(p_1=p_2=...p_k=\frac {1}{N}\)),信息熵达到最大值\(log_2N\),纯度最低;
当样本集合中只有类别\(i\)的样本,其他类别样本数量为0时(\ ...
西瓜书阅读笔记(目录)
西瓜书阅读笔记(目录)
西瓜书阅读笔记——第1章-绪论
西瓜书阅读笔记——第2章-模型评估与选择(到2.3.2)
西瓜书阅读笔记——第3章-线性回归(3.1-3.2)
西瓜书阅读笔记——第3章-对数几率回归(3.3)
西瓜书阅读笔记——第3章-线性判别分析(3.4)
西瓜书阅读笔记——第3章-多分类学习和类别不平衡问题(3.5、3.6)
西瓜书阅读笔记——第4章-决策树
西瓜书阅读笔记——第5章-神经网络
西瓜书阅读笔记——第6章-支持向量机(硬间隔6.1、6.2) | 冬于的博客 (ifwind.github.io)
西瓜书阅读笔记——第6章-支持向量机(软间隔6.4、6.5)
西瓜书阅读笔记——第6章-支持向量机(核函数6.3、6.6)
西瓜书阅读笔记——第3章-多分类学习和类别不平衡问题(3.5、3.6)
西瓜书阅读笔记——第3章-多分类学习和类别不平衡问题(3.5、3.6)
只记录和补充一些比较容易混淆、易忘、容易表述错误的内容。
多分类学习
考虑N个类别多分类学习的基本思路是“拆解法”,即将多分类任务拆为若干个二分类任务求解。
拆分策略:
一对一 One vs. One OvO
将N个类别两两配对,产生\(N(N-1)/2\)个二分类任务,新样本同时输入所有分类器,得到\(N(N-1)/2\)个分类结果,最终结果可通过投票法产生。
一对其余 One vs. Rest OvR
每次将一个类的样例作为正例,其他所有类的样例作为反例训练分类器,产生\(N\)个二分类任务。新样本输入所有分类器,若仅有一个分类器预测为正类,则对应类别标记为最终分类结果;若多个分类器预测为正类,通常考虑各个分类器的预测置信度,选置信度最大的类别标记作为分类结果。
因为OvO要训练更多的分类器,因此其存储开销和测试时间开销通常比OvR更大。但在训练时,OvR的每个分类器均使用全部训练样例,而OvO的每个分类器仅用到两个类的样例,因此,在类别很多时,OvO的训练时间开销通常比OvR更小。模 ...
西瓜书阅读笔记——第3章-线性判别分析(3.4)
西瓜书阅读笔记——第3章-线性判别分析(3.4)
强烈推荐配合西瓜书阅读使用的南瓜书和南瓜书作者录制的学习视频【吃瓜教程】《机器学习公式详解》(南瓜书)与西瓜书公式推导直播合集。
线性判别分析(Linear Discriminant Analysis,LDA)
二分类LDA模型
原理
给定训练样法将样例投影到一条直线上,使得:
同类样例的投影点尽可能接近;
异类样例投影点尽可能能远离。
在对新样本进行分类时,将其投影到该直线上,再根据投点的位置来确定样本的类别。
如下图所示:
对应到机器学习三要素中分别为:
模型:\(f(\mathbf x)=\mathbf w^T\mathbf x\)。
策略:经投影的类内方差尽可能小;经投影的异类样本中心尽可能远。
算法:拉格朗日乘子法求解\(\mathbf w\)的最优闭式解。
策略——构建loss function
经投影的类内方差尽可能小
假设属于两类的试验样本数量分别是 \(m_0\)和 \(m_1\),经投影的类内方差\(Var_{C_0}\)可表示为: \[
\begin{align ...
西瓜书阅读笔记——第3章-对数几率回归(3.3)
西瓜书阅读笔记——第3章-对数几率回归(3.3)
强烈推荐配合西瓜书阅读使用的南瓜书和南瓜书作者录制的学习视频【吃瓜教程】《机器学习公式详解》(南瓜书)与西瓜书公式推导直播合集。
线性分类模型
单调阶跃函数(unit-step function) Heaviside函数
不连续、不可微,若预测值大于零就判为正例,小于零则判为反例,预测值为临界值则可任意判别。
sigmoid函数——对数几率函数(logistic function)
sigmoid函数是形似S的函数。
对数几率函数是sigmoid函数的一种,单调可微,其表达式为: \[
y=\frac{1}{1+e^{-z}}
\] 与单调阶跃函数的图示关系如下图所示:
几率和对数几率
若将\(y\)视为样本作为正例的可能性,则\(1-y\)是其反例可能性,两者的比值\(\frac{y}{1-y}\)称为几率(odds),反映了\(\mathbf x\)作为正例的相对可能性.对几率取对数则得到"对数几率"(log odds,亦称logit):\(\ln\frac{y}{1-y}\)
...
西瓜书阅读笔记——第3章-线性回归(3.1-3.2)
西瓜书阅读笔记——第3章-线性回归(3.1-3.2)
强烈推荐配合西瓜书阅读使用的南瓜书和南瓜书作者录制的学习视频【吃瓜教程】《机器学习公式详解》(南瓜书)与西瓜书公式推导直播合集。
引言
在生活中经常会遇到的一些问题,比如犯罪现场留下的鞋码大概估计嫌疑人的身高;又比如通过一个程序员的发际线高度来判断这个程序员的计算机水平;再比如买西瓜的时候,通过某个西瓜色泽、根蒂、敲声等来判断西瓜是好瓜还是坏瓜等等。一个吃过或者见过很多不同类型西瓜的吃瓜人,往往可以根据鉴瓜经验去判断西瓜的好坏。
把上面过程抽象出来就是:
利用一个已经训练好的带参(θ)模型M(有经验的吃瓜人),根据样本的特征(西瓜色泽、根蒂、敲声等)预测样本的目标值(好瓜/坏瓜)。
那么要怎么成为一个有经验的吃瓜人呢?(也就是如何获得一个能解决目标问题的模型?)
可以通过品鉴不同的西瓜总结好瓜/坏瓜和西瓜特征之间的关系(模型通过观察大量与问题相关的样本,利用某种方式学习预测目标和特征之间的映射关系,或者说利用某种方式确定模型中的参数\(θ\))。
机器学习三要素
根据上面的逻辑,可以梳理出利用机器学习方法解 ...
西瓜书阅读笔记——第2章-模型评估与选择(到2.3.2)
西瓜书阅读笔记——第2章-模型评估与选择(到2.3.2)
记录和补充一些比较容易混淆、易忘、容易表述错误、以及方便取用的内容。
经验误差与过拟合
经验误差
误差error:学习器实际预测输出与样本真实输出之间的差异;
训练误差training error/经验误差empirical error:学习器在训练集上的误差;
泛化误差generalization error:在新样本上的误差。
过拟合、欠拟合
过拟合:在训练集上表现很好(过于好),但在测试集或者新样本上表现很差(泛化性很差),把在训练集中包含的不太一般的特性学到了(这些特性在整体样本空间中没有或者没那么重要,比如说训练集的噪声);
欠拟合:在训练集上就表现很差,模型学习能力低下。
模型评估与选择
对候选模型的泛化误差进行评估,选择泛化误差最小的模型。我们无法直接获得全部的样本空间,因此泛化误差是无法准确计算的,所以我们根据已有的数据集构建测试集来估计泛化误差。
留出法hold-out
获得的所有样本数据)划分为两个互斥的集合,将其中一个作为训练集S,另一个作为验证集T,即D=SUT,S∩T=Φ。在S ...
西瓜书阅读笔记——第1章-绪论
西瓜书阅读笔记——第1章-绪论
只记录和补充一些比较容易混淆、易忘、容易表述错误的内容。
基本概念
分类classification、回归regression、多分类multi-classification、聚类clustering
分类-预测离散值(有监督):西瓜是“好瓜”或“坏瓜”;树的类别是梧桐或三球悬铃木或银杏;
回归-预测连续值(有监督):西瓜成熟度0.95、0.37;树高1.4米、3.2米。
多标签分类(有监督):某个样本可以有多个标签,比如一棵树是银杏且是黄色,另外一棵树是三球悬铃木且是黄色。
聚类(无监督):学习过程中使用的训练样本不拥有标记信息。
训练training、验证validation/develop、测试testing
学得模型后,使用其进行预测的过程称为测试。
为什么要将数据集划分为三个部分?三个部分的作用?三个部分数据集的比例应如何设定?
另外一种常见的数据集划分方法是将数据集划分为两个部分(训练集和测试集),这种划分方法存在的问题在于,模型利用训练集数据进行训练,测试集数据进行模型泛化性测试。但我们不能利用测试集测试的bad ca ...
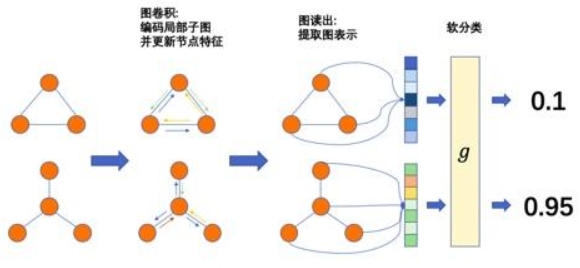
图神经网络的下游任务3-图分类
图神经网络的下游任务3-图分类
引言
在之前已经知道如何利用图神经网络进行图级别的表示学习。利用GNN学习到的图表示,我们可以进行第三类下游任务——图分类。这与节点分类的道理是类似的。
在这篇博客中,我们将首先介绍图分类任务,借助这个下游任务,学习如何在pytorch和PyG的DataLoader类实现mini-batch,并补充几个编写GNN或者其他深度学习代码常用的步骤。
看完以后可以掌握以下内容:
使用pytorch和PyG批量化处理大小各异的图数据;
利用图神经网络实现图分类任务;
完整的利用GNN进行下游任务的代码框架,包括:
DataLoader实现mini-batch;
日志文件、可视化;
scheduler管理optimizer;
模型的保存和断点继续训练;
模型预测。
图分类概述
图分类定义
图分类其实和节点分类相似,本质就是预测图的标签。根据图的特征(比如图密度、图拓扑信息等)、已知图的标签,对未知标签的图做类别预测。
图分类应用意义
它的应用广泛,可见于生物信息学、化学信息学、社交网络分析、城市计算以及网络安全 ...
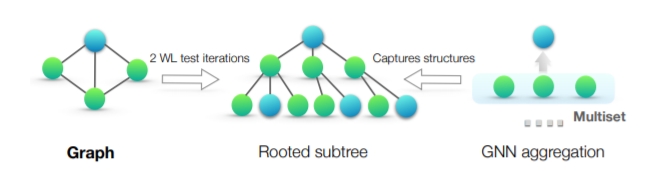
GIN:逼近WL-test的GNN架构
GIN:逼近WL-test的GNN架构
引言
之前提到了如何设计图神经网络进行节点表征学习,并基于此开展下游任务1节点分类和下游任务2链路预测。
本篇博文将关注利用GNN进行图级别表示的学习。图表征学习要求根据节点属性、边和边的属性(如果有的话)生成一个向量作为图的表征,基于图表征可以做图的预测。基于图同构网络(Graph Isomorphism Network, GIN)的图表征网络是当前最经典的图表征学习网络。
本文将以GIN为例,首先将介绍图同构的相关概念,然后介绍图同构测试的经典算法——Weisfeiler-Lehamn算法,接着解释为什么说GNN是WL-test的变体,并分析基于消息传递网络架构设计的GNN模型如何学习图表征,而现有的GNN模型如GCN等为什么达不到WL-test,最后介绍How Powerful are Graph Neural Networks?一文中作者提出的GIN架构,并提供相应模块的代码。
看完以后应该可以回答以下几个问题:
什么是同构图?
为什么要计算图同构?
什么是WL-test?
GNN与WL-test的相似之处?
为什 ...