智能客服的核心技术-对话系统
智能客服的核心技术-对话系统
对话系统:与真人进行对话的系统。
这里首先用案例介绍一下对话系统的基本概念,然后重点介绍任务型对话系统的。
基本概念
这里举一个小例子,结合一起来理解对话系统的相关概念。
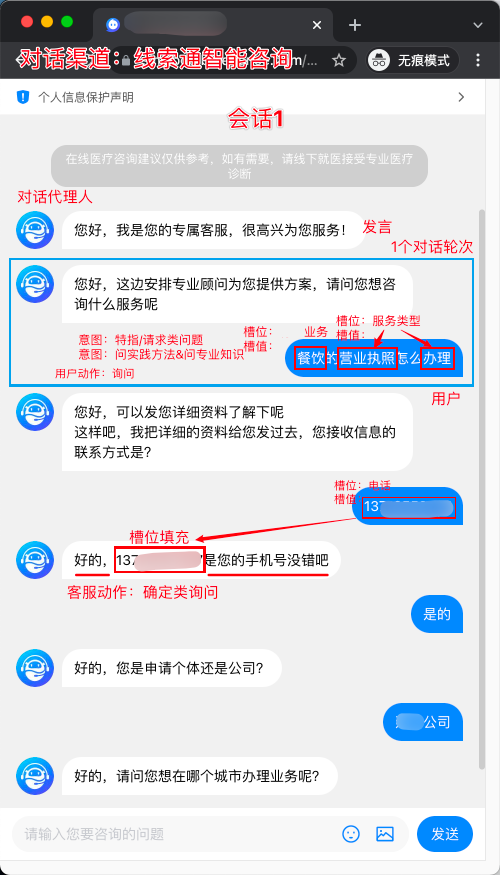
用户 (User):指产品或服务的使用者。
对话代理人 (Agent):对话代理人既可以是真人,如客服人员、客户支持代表,也可以是虚拟人,如机器人。在对话系统内部,因其设计目的不同,Agent既可用于解决单领域 (single-domain) 问题,也可用于解决多领域 (multi-domain) 问题。
发言 (Utterance):在对话中,对话代理人与用户任何一方说出的任意一句话。
对话轮次(Turns):一来一回合称一轮turn,来回多次称为多轮对话。
会话(Session):由一个用户发起的某次多轮对话。会话是对话代理人与用户之间发生的一次连续对话,不同对话系统可以有自己对「连续」的定义。
对接渠道 (Channel):对话代理人本身只负责对话逻辑,并不包含对接渠道(对话载体),如钉钉、美洽、飞书、Slack 等等。
意图 (Intent):意图是系统能够识别的最小的用户目的,是系统决策的基本元素之一。只有在识别用户发言背后的含义后,机器人才能决定回复什么。剧本中的每一章节由用户意图的识别和机器人采用的回答构成。从发言的角度出发,意图约等价于发言中的动词。如「下周我要飞去上海」中的「飞」就是意图。
实体/槽值/槽位填充物 (Entity/Slot value/Slot filler):实体和领域息息相关,如票据这样的实体几乎不会出现在点餐机器人系统中;有些实体则比较通用,比如时间、地点、数字等等。和领域相关的实体需要单独定义,通用实体则可以由平台统一支持。
槽位 (Slot):盛放实体/槽值信息的容器为槽位,信息本身为槽位填充物 (slot filler)。想象填写一张表格,表中的每个空就是槽位,填写的内容就是槽位填充物。 槽位和实体的区别是什么? 实体指的是从单句发言中提取到的信息,而槽位存储整个会话过程中提取到的所有信息,前者是后者的数据来源,槽位存储的信息会被用于后续对话系统决策的过程中。
动作 (Action):理解用户的意图后,对话代理人除了回复消息外,可能需要帮助用户去做一些动作,比如:修改日程、注销账号等。不同领域的对话代理人需要执行的动作不同,需要定制化开发。在设计中,机器人回复消息通常也会被认为是一种动作。
对话系统的应用场景

| 问答 | 助手 | 聊天 |
|---|---|---|
| 常见于智能客服系统,问题和答案都比较固定,背后常常与知识库挂钩。 甚至可以将问答系统理解成是用对话的方式快速检索使用文档中的 frequently asked question (FAQ)。 在问答场景中,用户明确地知道与之对话的不是真人,因此也不会使用复杂的对话结构,主要以单轮对话的形式呈现,用户占主导。 |
助手场景常见于智能设备上的语音助手,如 Siri 等,它的问题和答案相对固定,背后也可能与知识库挂钩。同时,助手需要和许多三方服务对接,以完成用户交付的任务,因此也常常被称为任务机器人 (task bot)。 但与问答场景不同,助手面对问题给出的答案或做出的行动可能随着用户输入的信息变化而变化。比如用户要订机票,助手需要知道出发地、目的地、时间、舱位等信息,这些信息不同,助手最终完成的任务不同。此外,在人们的真实对话中,将这些信息在一句话中说出并不符合人们说话的习惯,因此助手与用户之间往往要进行多轮对话。 在助手场景中,尽管用户明确知道对方是机器人,但对话过程相比于问答更加自然一些。 通常用户在开启会话时会带着明确的目的,会话结束时,目的即可能达成,也可能未达成,而未达成目的的对话就是对话设计者需要重点关注的内容。 |
聊天场景指的是像人一样与人交谈,市面上存在的系统有贤二机器僧、微软小冰等。理论上,聊天不存在固定内容,天南海北都可以侃。著名的图灵测试就是用于验证机器是否可以让人无法分辨他是在和人聊天还是在和机器聊天。 在聊天场景中,对话系统面对的挑战与前二者相比要复杂很多,如自然语言理解能力、记忆能力、知识面,甚至语气、性格等等,但它提供的对话体验也最接近与真人交谈。 |
对话系统的常见构建方式
| 基于规则的对话系统 | 基于语料的对话系统 | 混合型对话系统 | |
|---|---|---|---|
| 结构 |  强规则:预先根据领域知识设定一些规则,用户输入文本后,系统根据规则的优先级逐条比对,符合规则条件后,根据预设的模板拼接出响应。 比如这里有两个规则: (You $0$ Me) → (What makes you think I $0$ You) (I $1$) → (You say you $1$) 可以生成下面的对话: U → 用户,E → ELIZA U: You hate me. E: What makes you think I hate you?... U: I know everybody laughed at me. E: You say you know everybody laughed at you.... |
 准备大量真实环境的对话数据,根据这些数据训练出对话模型再投入使用。 训练的对话模型分为两类: 信息检索:将所有对话转化成常用的自然语言特征,如基于词频的 tf-idf 或基于语义的 embedding,然后将这些特征存入通用搜索引擎或向量检索引擎中。收到用户发言后,先将文本做相同的向量化处理,然后再通过上述引擎检索举例最近的对话,将回答返回给用户。基于信息检索的模型只能生成训练数据中已知的回答,相比基于规则的模型,它不需要逐条地维护规则,而是将规则通过穷举的方式沉淀在数据集中。 统计模型:将所有对话输入到统计机器学习模型中,如 Transformer,通过有监督训练得到语言模型,这类语言模型可以通过预测的方式生成回答,它的回答中可能出现训练数据中不存在的语句。 |
将基于规则和基于语料的方案融合。 一个典型的例子:使用统计模型做句子中的内容提取,对话行为识别,使用规则生成回答。这种做法既可以保持对内容的语义级别理解,又能够控制回答的风险,避免生成行为的不稳定。 |
| 优点 | 1. 开发速度快、成本低、易集成 2. 行为稳定、可解释,安全可控风险小 3. 能发送多媒体信息、图片、视频 推理时间短、速度快 |
1. 系统维护成本低,训练完后无需其它维护成本 2. 具备自然语言理解能力,能识别同义语句的不同表达 3. 新增语言支持成本低,因为开源社区中已存在不同自然语言预训练好的特征提取工具 |
1. 规则和语料训练的模型可以互补: 加入了规则进行约束,相比纯语料模型更可控 2. 相比规则模型具有一定的自然语言理解能力,可能可以面对一些规则无法cover的问题 |
| 缺点 | 1. 维护成本高,需要人工维护规则和优先级,复杂度高了以后难以管理 2. 不具备自然语言理解能力,同义语句无法触类旁通,需要穷举规则 3. 新增语言支持成本高 |
1. 开发周期长、成本高、需要大量训练数据 2. 训练数据问题可能导致系统行为不稳定,风险不可控,garbage in garbage out 线上模型推理时间长,占用资源多 3. 不支持多媒体消息,只能发送文本或文本合成的语音 |
1. 规则和语料训练的模型冲突的情况可能影响会话 2. 规则和模型的trade-off |
混合型对话系统的常见结构
接下来,介绍一下混合、任务型对话系统的经典架构。
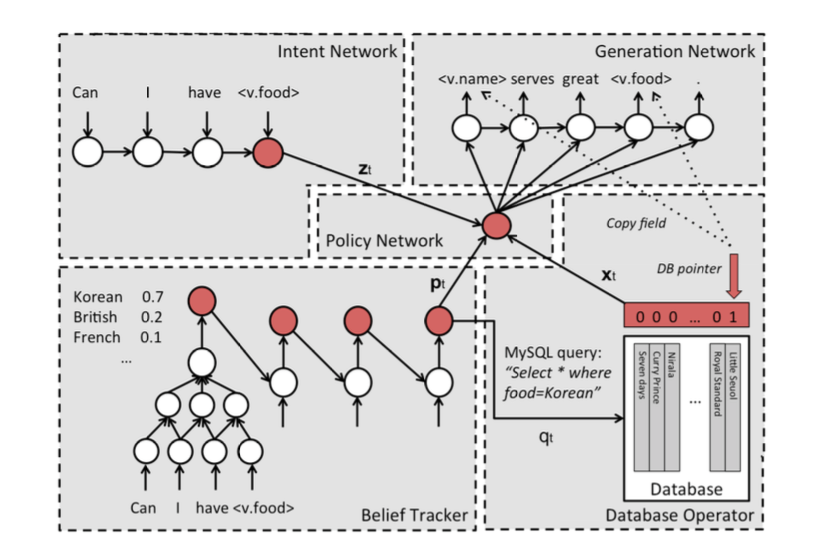
任务型对话系统pipline型经典架构
任务型的agent代替用户做一系列的操作以完成用户的任务。
agent完成某一项任务要做的一系列操作,需要一揽子信息。
比如说:
- 用户需要点一杯咖啡(意图),agent需要知道以下几个信息(槽位):咖啡类型,大小,冰度,才能完成点咖啡的任务。
- 因此在对话过程中,通过历史对话状态,判断当前是什么对话状态(意图、槽位对应的槽值/有哪些槽位信息已知/还有哪些槽位需要问用户);
- 并且根据当前的对话状态,去生成下一步的系统动作(比如回答用户的问题、和用户确认槽值、询问下一个槽位等等);
- 直到完成用户任务的所有信息都明确了,完成当前对话。
| 任务型对话系统pipline型经典架构 | 任务型对话系统案例 |
|---|---|
 |
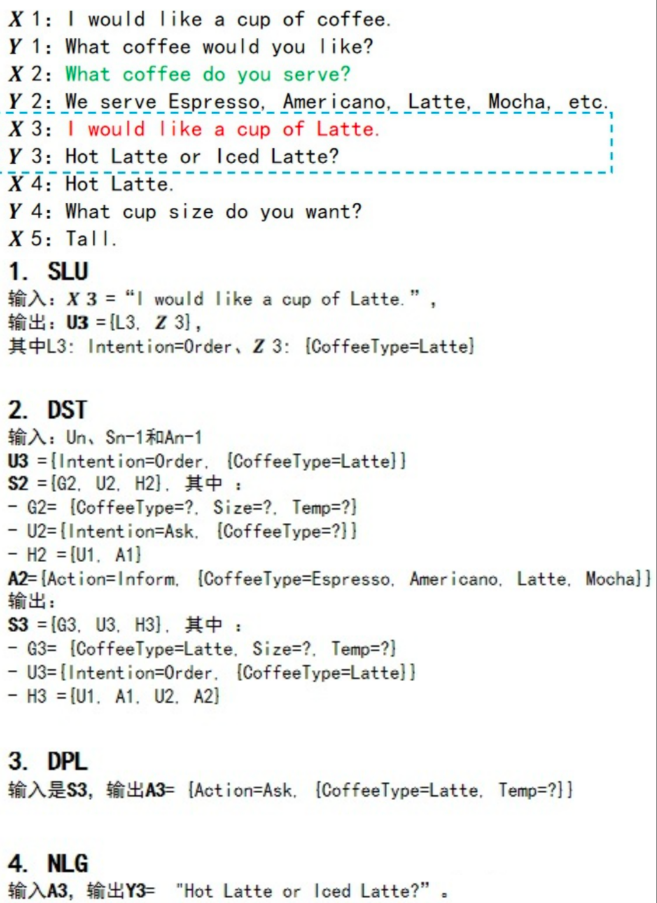 |
语音识别Automatic Speech Recognition (ASR)
ASR 模块负责将用户输入的音频转化为文本,得到用户发言的文本。
⚠️ 如果对话系统仅需支持文本对话则无需 ASR 模块,因此在架构图中用虚线表示
自然语言理解Natural Language Understanding (NLU)
NLU 模块负责从用户的发言中解析出对话中包含的关键信息,如领域、意图、实体等等。
输入:代表用户输入的Utterance,\[X_n\] 输出:\[U_n=(I_n,Z_n)\],其中\[I_n\]为意图,\[Z_n\]为槽值对。
主要模型任务:
- 领域识别任务:文本分类
- 意图识别任务:文本分类
- 槽位识别任务:命名实体识别
可以单个任务训练多个模型,也可以多任务联合训练一个模型。
对话管理Dialogue Management (DM)
DM 模块负责管理当前对话的状态 (State,\[S_{n}\]) 和策略 (Policy),包括对话状态追踪DST和对话策略DP两个部分。
对话状态追踪Dialogue State Tracking(DST)
对话状态包括用户与agent之间的历史聊天记录以及关键信息。DST根据对话历史,维护当前对话状态。
输入:\[U_n=(I_n,Z_n)\],\[A_{n-1},S_{n-1}\] 输出:\[S_{n}=\{G_n,U_n,H_n\}\]其中\[G_n\]为用户目标,\[H_n\]为聊天历史
分为两种情况:
具有预定义的槽名称和值,每一轮DST模块试图根据对话历史找到最合适的槽值对。可以将DST简化为分类问题。

没有固定的槽值列表,因此DST模块尝试直接从对话上下文中查找槽值或根据对话上下文生成槽值。
对话策略Dialogue Policy(DP)
策略是根据状态输出回复的函数,根据当前对话状态输出下一步系统动作。
输入:\[S_{n}=\{G_n,U_n,H_n\}\]其中\[G_n\]为用户目标,\[H_n\]为聊天历史,可以包括
双方的对话历史
系统和外部注入的事件
表单 (form) 信息
…
输出:\[A_{n}=\{A_i,V_i\}\]其中\[A_i,V_i\]为第\[i\]轮对话的attribute和value
常见的对话策略,如剧本、监督学习、增强学习。
剧本 (Story)
剧本是在对话设计中设定的模板,提前设定好用户在不同意图下机器人执行相应的动作,比如:
story:
steps:
- intent: arrange_meeting
- action: update_calendar
- action: utter_arrange_meeting上面这个剧本说的就是:机器人在识别用户发言中的意图是举办会议 (arrange_meeting) 时,先执行更新日历 (update_calendar) 的动作,再执行回复用户 (utter_arrange_meeting) 的动作。
通常一个会话对应一个剧本,比较灵活的对话系统可以支持在一个会话中通过上下文切换 (context switch) 演绎多个剧本。
强化学习(Reinforce learning)
基本概念review
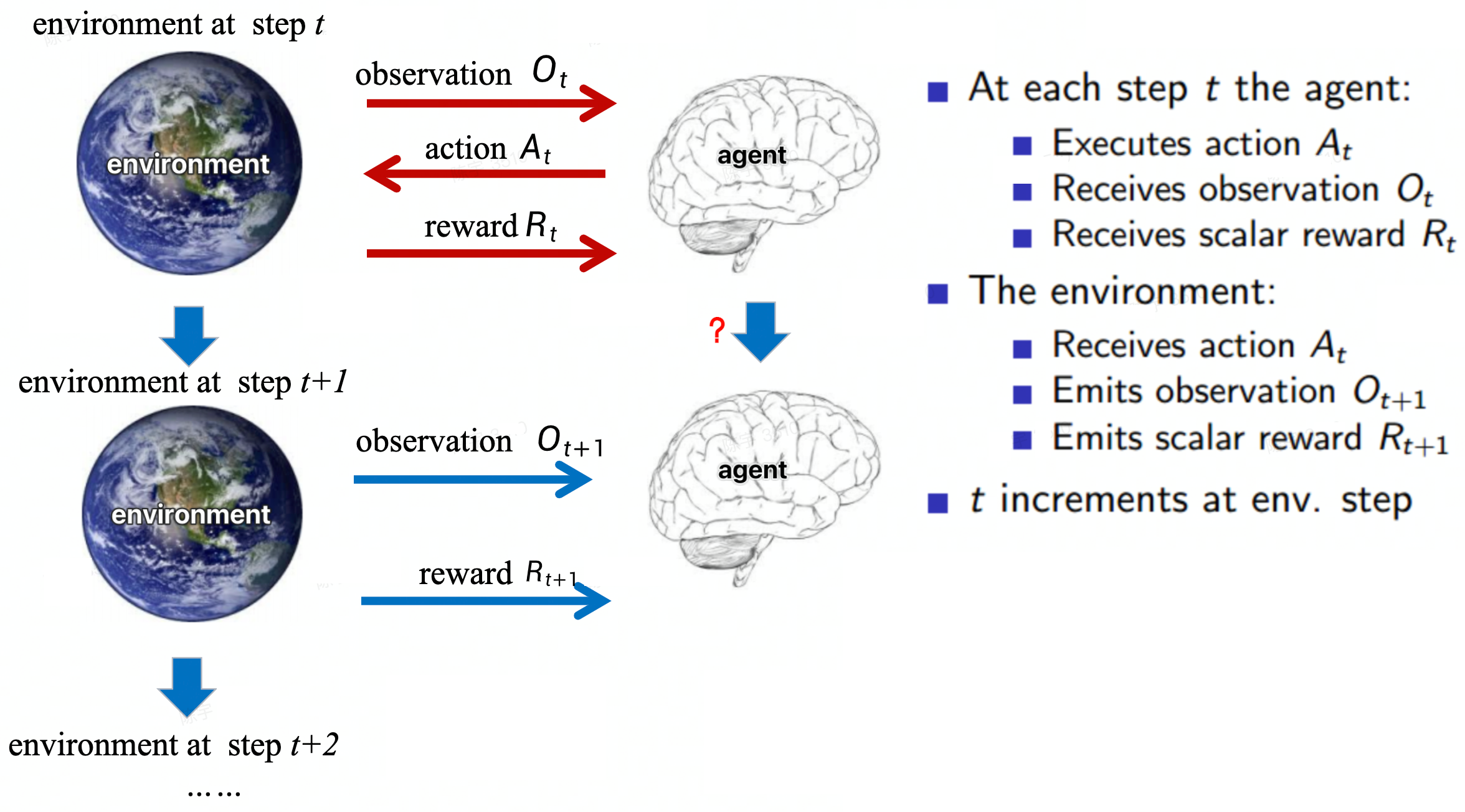
目标是找到一个最优的策略 Policy 使得agent获得的 Reward 最多。
Policy based
模型:直接训练策略(actor),把state输入到actor中,输出action的分布
策略,如何判断actor的好坏(训练目标):
根据当前actor去完成一整轮,得到一整轮的reward(具有随机性,需要转化为求reward的期望)
算法:梯度上升法求解最大化reward的参数。
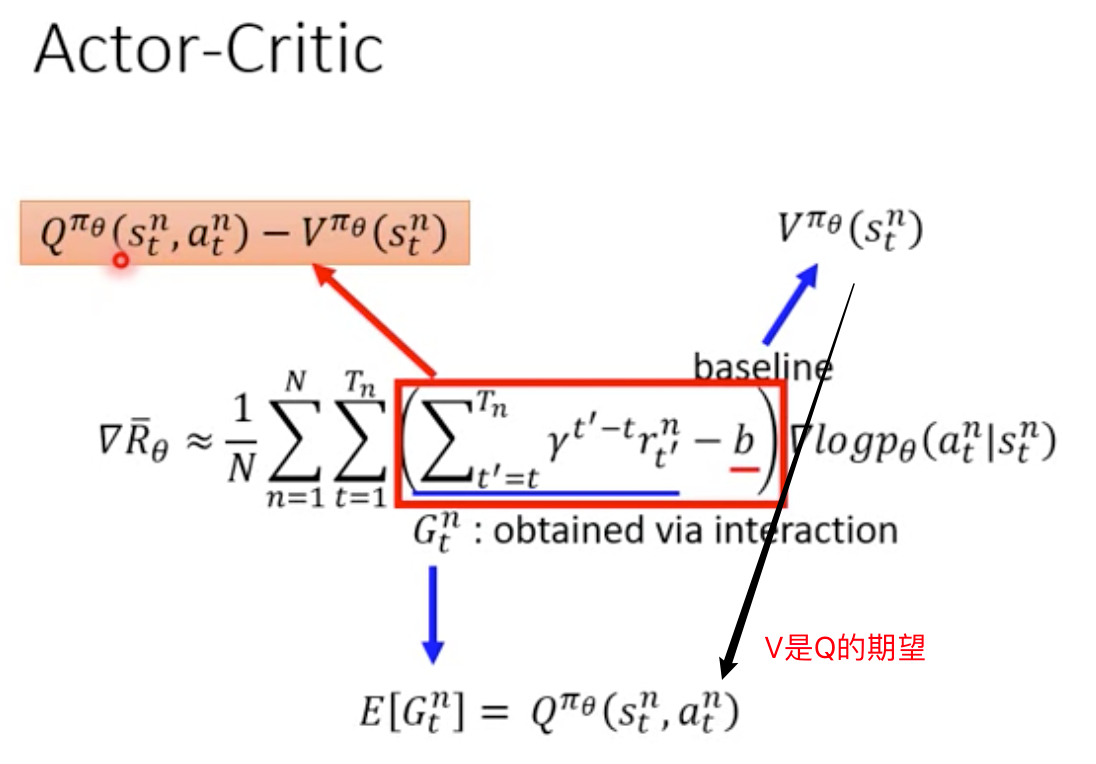
Value based
模型:间接求,learn critic
策略:把state输入critic,输出看到当前state以后到episode结束的累积reward的期望是多少=value function
Value function又有两种:
只与当前的state有关V(s) 与当前的state和action有关Q(s,a)(Q function) 
 V(s)是Q(s,a)的期望
V(s)是Q(s,a)的期望
在state s里面不一定会采取action a,但是用能得到最大累计reward的action a来计算Q valuePolicy based+Value based=Actor Critic
模型:互动的过程具有很大的随机性,直接根据互动的过程可能结果不会好,不要直接跟环境的reward学,而是让actor跟critic学。
RL如何应用到对话系统中?
对话系统目的是利用agent管理客服对当前用户消息进行什么样的答复。形成完整的答复需要和NLG的配合,RL需要给NLG传入的东西就是RL需要学习的部分。所以DST估计的对话状态=agent状态,通过RL学习策略,针对预设的候选动作集,选择agent的动作,NLG再根据agent的动作和状态生成话术。
一般任务型的对话系统,是封闭域的任务,给定了有限个数的意图/槽位类别,动作空间是离散的。
自然语言生成Natural Language Generation (NLG)
当对话代理人做完决定后,需要把它想回复的内容转化成自然语言,这一步骤就由 NLG 模块负责完成。
输入:\[A_{n}=\{A_i,V_i\}\] 输出:\[Y_{n}=\{y_1,y_2,y_3...\},y_i\]表示第\[i\]轮对话的回复response
NLG 有两种方案:基于模板和基于统计。
基于模板(可控性比较强)
基于模板的生成方案中,对话代理人的所有发言都由人工设计而成,然后将剧本中的上下文信息,如槽位填充物,填入模板。举例如下:
const template = "What time do you want to leave %s"
const slotCityOrig = "Beijing"
const uterrance = fmt.Sprintf(template, slotCityOrig)通常为了让回复不那么呆板,会为同一个回答预置多个模板,然后在回复时通过一些策略选取一个。
基于统计(表达更丰富)
基于统计生成的目标就是在大量标注语料训练后,能够自动生成含义相同、表述不同的发言,如:
\1. Au Midi is in Midtown and serves French food.
\2. There is a French restaurant in Midtown called Au Midi.基于统计的生成方案需要大量的训练数据,这些数据本身很难获取,难度体现在两方面:
- 在某领域的对话代理人上线之前,很难获得和生产环境相近的数据
- 以上面的句子为例,如果要训练一个点餐机器人,那么要找到包含所有饭店、地点和菜色组合的语料几乎不可能
因此有一种比较常用的技术叫“去词化”delexicalization,即将句子中的实体替换成实体类型,如:
\1. $restaurant_name is in $neighborhood and serves $cuisine food.
\2. There is a $cuisine restaurant in $neighborhood called $restaurant_name.在训练时使用实体类型,预测时将实体真实取值填入即可,后者被称为 relexicalize。
Text To Speech (TTS)
TTS 模块负责将对话代理人的回复发言转化成语音。
⚠️ 如果对话系统仅需支持文本对话则无需 TTS 模块,因此在架构图中用虚线表示
端到端的对话系统
受开放域对话领域启发,使用模型以端到端的方式而不是分模块优化的方式构建任务型对话系统。
大多数端到端任务型对话系统采用seq2seq框架,但端到端任务型对话系统因为要和知识库交互,不等于seq2seq模型。
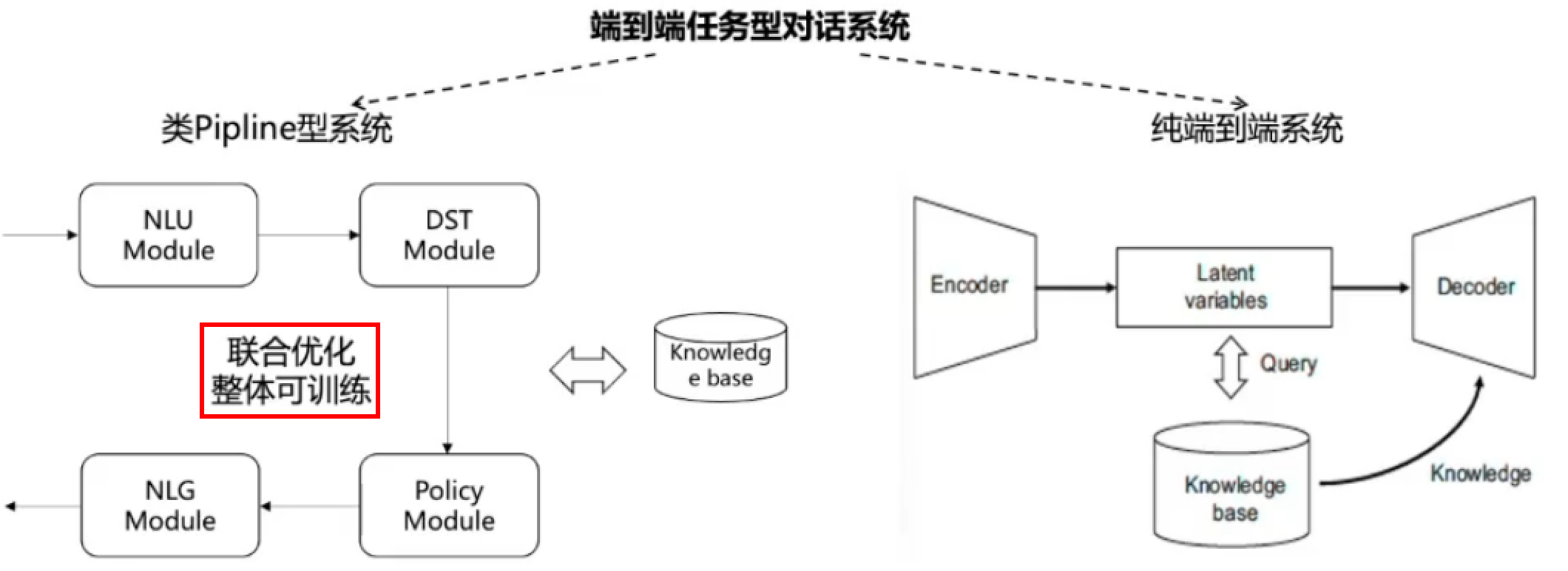
类pipeline型:把pipeline当作一个大模型整体训练
纯端到端型
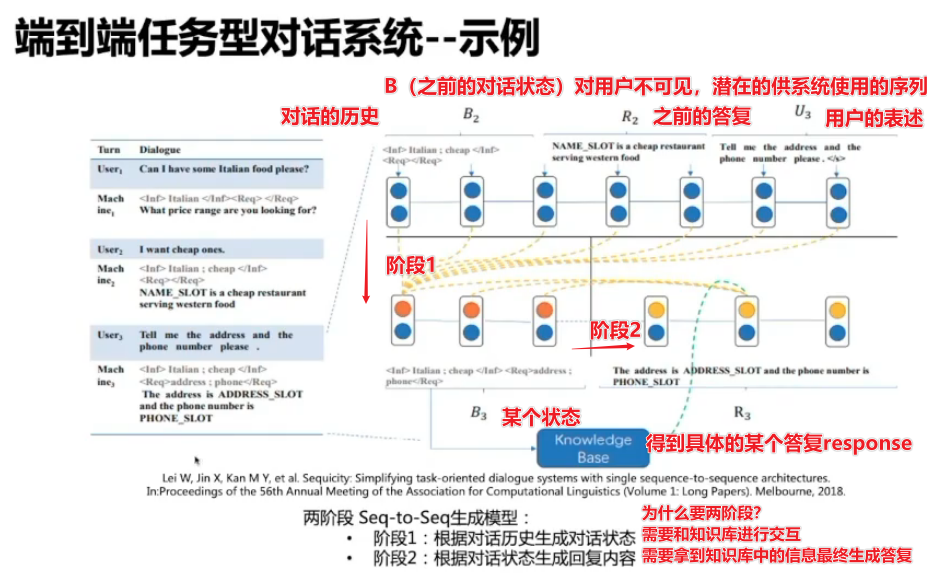
端到端任务式对话系统与知识库交互结构化问答的区别:
前者以任务完成为目标,任务型对话,完成一次订票,需要通过查数据库进行答复(比如还有多少张票,有什么时候的票),但是答复本身(是否订票成功)不是数据库知识,而结构化的问答的答案是回答有没有票。
对比
任务型pipeline对话系统和纯端到端对话系统的对比如下:
| 对比角度 | pipline型 | 纯端到端型 |
|---|---|---|
| 需要的标注数据量(主要是考虑数据类型) | 多,四个任务需要不同的标注数据 | 少 |
| 可解释性 | 强,各步骤/子模块分工明确 | 弱 |
| 稳定性(可控性) | 强,可加入规则限定 | 弱 |
| 商业系统中使用 | 多 | 少 |
| 系统优化 | 子模块分别优化 | 少 |
| 与数据库交互 | 容易 | 难 |
| 错误累积传播 | 存在 | 不存在 |
