Transformer/BERT/实战
Transformer/BERT/实战
Transformer相关
Transformer相关——(1)Encoder-Decoder框架
Transformer相关——(2)Seq2Seq模型
Transformer相关——(3)Attention机制
Transformer相关——(4)Poisition_encoding
Transformer相关——(5)残差模块
Transformer相关——(6)Normalization方式
Transformer相关——(7)Mask机制
Transformer相关——(8)Transformer模型
Transformer相关——(9)训练Transformer
Transformer相关——(10)Transformer代码分析
BERT相关
BERT相关——(1)语言模型
BERT相关——(2)Contextualized Word Embedding和ELMO模型
BERT相关——(3)BERT模型
BERT相关——(4)GPT-2模型
BERT相关——(5)Pre-train_Model
B ...

Pytorch手册汇总
Pytorch手册汇总
Pytorch自查手册
Pytorch与深度学习自查手册1-张量、自动求导和GPU
Pytorch与深度学习自查手册2-数据加载和预处理
Pytorch与深度学习自查手册3-模型定义
Pytorch与深度学习自查手册4-训练、可视化、日志输出、保存模型
Pytorch与深度学习自查手册5-损失函数、优化器
Pytorch与深度学习自查手册6-网络结构、卷积层、attention层可视化
Pytorch与深度学习训练trick实战
Pytorch与深度学习训练trick实战
竞赛总结汇总
竞赛总结汇总
NLP竞赛
天池-零基础入门NLP-文本分类
Task1&Task2 数据读取与数据分析
Task3-基于机器学习的文本分类
Task4-基于深度学习的文本分类1-FastText
Task4-基于深度学习的文本分类2-Word2Vec
Task4-基于深度学习的文本分类2.2-Word2Vec+TextCNN+BiLSTM+Attention分类
Task4-基于深度学习的文本分类3-基于Bert预训练和微调进行文本分类
CV竞赛
Pytorch与视觉竞赛入门
Pytorch与视觉竞赛入门1-网络层原理和使用
Pytorch与视觉竞赛入门2.1-PyTorch激活函数原理和使用
Pytorch与视觉竞赛入门2.2-PyTorch常见的损失函数和优化器使用
Pytorch与视觉竞赛入门3.1-使用Pytorch搭建VGG
Pytorch与视觉竞赛入门4-PyTorch完成Fashion-MNIST分类
Pytorch与视觉竞赛入门5-PyTorch搭建对抗生成网络
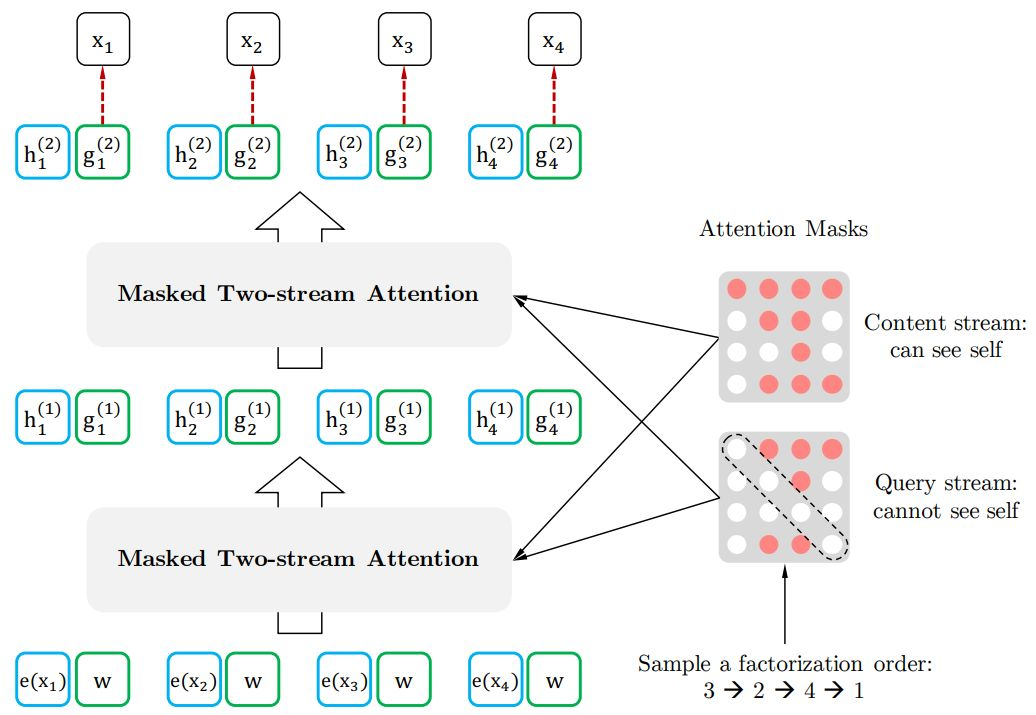
排列语言模型XLNET
排列语言模型XLNET
引言
本文首先会介绍什么是自回归语言模型&自编码语言模型以及相应的经典模型、优缺点,然后将介绍XLNET的模型结构,说明其如何结合两类语言模型的优点。
自回归语言模型(Autoregressive LM)
自回归语言模型是指根据上文内容预测下一个可能的单词(从左向右),或者根据下文预测前面的单词(从右向左)的语言模型任务,典型的自回归语言模型。
经典模型
ELMO、GPT系列、XLNET; 特别注意ELMO虽然同时利用了双向的信息,但是其本质仍是自回归语言模型。因为ELMO实际上是两个方向(从左到右以及从右到左)的自回归语言模型,将两个方向的LSTM的隐节点状态拼接到一起体现双向语言模型,所以其实是两个自回归语言模型的拼接,本质上仍属于自回归语言模型。
优点
自回归语言模型天然匹配生成类下游NLP任务,比如文本摘要,机器翻译等,这些任务在实际生成内容的时候,就是从左向右的。而Bert这种DAE模式,在生成类NLP任务中,面临训练过程和应用过程存在不一致,导致自编码语言模型在生成类的NLP任务做得不太好。
缺点
只能利用上文或者下文的信 ...
Pytorch与深度学习自查手册6-网络结构、卷积层、attention层可视化
Pytorch与深度学习自查手册6-网络结构、卷积层、attention层可视化
网络结构可视化
torchinfo工具包可以用于打印模型参数,输入大小,输出大小,模型的整体参数等,类似keras中的model.summary()。
使用torchinfo可视化网络结构
安装torchinfo
# 安装方法一pip install torchinfo # 安装方法二conda install -c conda-forge torchinfo
使用torchinfo
只需要使用torchinfo.summary(),必需的参数分别是model,input_size[batch_size,channel,h,w],更多参数可以参考documentation。
import torchvision.models as modelsfrom torchinfo import summaryresnet18 = models.resnet18() # 实例化模型summary(model, (1, 3, 224, 224)) # 1:batch_size 3:图片的通道数 224 ...

Pytorch训练代码框架
Pytorch训练代码框架
前言
自己在学习和coding的过程中,感觉每次搞一个模型,需要写一堆的过程代码(大部分是可复用的),有的时候还需要从之前或者各个博客cv一点代码,这样开发起来效率可能比较低,所以整理了一份相对来说比较全面的Pytorch建模&训练框架,一些简单的trick也整理放在了里面,方便取用。
因为个人用NLP比较多,这个框架主要也是在预训练+微调这一范式下写的,但是想去掉预训练模型也很好改,就不多赘述了。
代码框架不是很成熟,主要是从自己开发过程中进行一些总结,欢迎大家提issue,我也会持续更新,希望也可以帮助一些有需要的朋友~
完整代码:code_frameword_pytorch
Pytorch手册汇总:Pytorch手册汇总
安装包依赖
见requirement.txt
transformers==4.9.0datasets==1.11.0torch==1.7.1sklearn==0.21.3
补充一下,命名实体识别任务中常用到pytorch-crf包,用下面的方式安装:
pip install pytorch-crf==0. ...
Pytorch与深度学习训练trick实战(持续更新)
Pytorch与深度学习训练trick实战(持续更新)
冻结参数
def set_parameter_requires_grad(model, feature_extracting): if feature_extracting: for param in model.parameters(): param.requires_grad = Falsefeature_extract = Trueset_parameter_requires_grad(model, feature_extract)
学习率相关
动态调整学习率
# cosine lr_lambdalambda_cosine = lambda x: ((1 + math.cos(x * math.pi / args.epochs)) / 2) * (1 - lrf) + lrf # cosinescheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda_cosine)
warmup
# warm up lr ...
智能客服的核心技术-对话系统
智能客服的核心技术-对话系统
对话系统:与真人进行对话的系统。
这里首先用案例介绍一下对话系统的基本概念,然后重点介绍任务型对话系统的。
基本概念
这里举一个小例子,结合一起来理解对话系统的相关概念。
用户 (User):指产品或服务的使用者。
对话代理人 (Agent):对话代理人既可以是真人,如客服人员、客户支持代表,也可以是虚拟人,如机器人。在对话系统内部,因其设计目的不同,Agent既可用于解决单领域 (single-domain) 问题,也可用于解决多领域 (multi-domain) 问题。
发言 (Utterance):在对话中,对话代理人与用户任何一方说出的任意一句话。
对话轮次(Turns):一来一回合称一轮turn,来回多次称为多轮对话。
会话(Session):由一个用户发起的某次多轮对话。会话是对话代理人与用户之间发生的一次连续对话,不同对话系统可以有自己对「连续」的定义。
对接渠道 (Channel):对话代理人本身只负责对话逻辑,并不包含对接渠道(对话载体),如钉钉、美洽、飞书、Slack 等等。
意图 (Intent):意图是系统 ...

《统计学习方法》阅读笔记——第6章-逻辑斯谛回归与最大熵模型
统计学习方法笔记——第6章-逻辑斯谛回归与最大熵模型
逻辑斯谛回归模型logistic regression
虽然叫回归模型但是是经典的分类方法之一,属于对数线性模型。
逻辑斯谛分布logistic distribution
设\(X\)是连续随机变量,\(X\)服从逻辑斯谛分布是指\(X\)具有下列分布函数和密度函数: \[
\begin{align}F(x)=P(X\leq x)=\frac{1}{1+e^{-(x-\mu)/\gamma}}\\
f(x)=F'(x)=\frac{e^{-(x-\mu)/\gamma} }{\gamma(1+e^{-(x-\mu)/\gamma})^2}
\end{align}
\] 式中,\(\mu\)为位置参数,\(\gamma>0\)为形状参数。图形如下图所示,分布哈数曲线以点\((\mu,\frac{1}{2})\)为中心对称,曲线在中心附近增长速度较快,在两端增长速度较慢。形状参数7的值越小,曲线在中心附近增长得越快。
二项逻辑斯谛回归模型
二分类模型,为如下的条件概率分布,通过监督学习的方法来估计模 ...
《统计学习方法》阅读笔记——第5章-决策树
统计学习方法笔记——第5章-决策树
决策树
决策树模型
决策树模型呈树形结构,在分类问题中,表示基于特征对实例进行分类的过程。决策树学习本质是从训练数据集中归纳出一组分类规则。
决策树由结点(node)和有向边(directed edge)组成。结点有两种类型:内部结点(internal node)和叶结点(leaf node)。内部结点表示一个特征或属性,叶结点表示一个类。
决策树模型可以认为是 if-then 规则的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。
决策树的路径或其对应的 if-then 规则集合具有一个重要的性质:互斥并且完备。每一个实例都被一条路径或一条规则所覆盖,而且只被一条路径或一条规则所覆盖。
决策树对应于给定特征条件下类的条件概率分布\(P(Y|X)\)时(\(X\) 取值于给定划分下单元的集合,\(Y\) 取值于类的集合),示例如下图所示,决策树的一条路径对应于划分中的一个单元。
决策树策略
需要的是一个与训练数据矛盾较小的决策树,同时具有很好的泛化能力。决策树学习用损失函数表示这一目标,损失函数通常是正则化的极大似然函 ...