消息传递图神经网络(Message Passing Neural Networks,MPNN)
消息传递图神经网络(Message Passing Neural Networks,MPNN)
一、引言
消息传递图神经网络(Message Passing Neural Networks,MPNN)实质上应该说是一种从具体的图神经网络模型中抽象出来的图神经网络框架(范式),其前向传播包括消息传递(message passing)和读出(readout)两个阶段。[论文原文:Neural Message Passing for Quantum Chemistry]
接下来将先整体介绍该框架并说明消息传递和读出两个阶段的区别;然后将详细介绍两个阶段的步骤,并对比基于该框架设计的实例模型中是如何设计消息传递和读出两个阶段的;最后提供一个代码改写框架方便利用该范式进行模型设计和编写代码。
看完后应该可以回答以下几个问题:
- 消息传递图神经网络完整的框架长什么样?
- 框架每个阶段和步骤在做什么?
- 基于该框架设计的模型在代码中应该如何实现?
二、消息传递图神经网络框架
消息传递图神经网络包括消息传递(message passing)和读出(readout)两个阶段。其中消息传递阶段包括两个核心函数(消息函数(Message function/Aggregation Function)、更新函数(Update function/Combination Function)),其主要目的是学习图中节点的特征;而读出阶段包括一个核心函数(读出函数(Readout function)),其主要目的是得到整个图的特征。
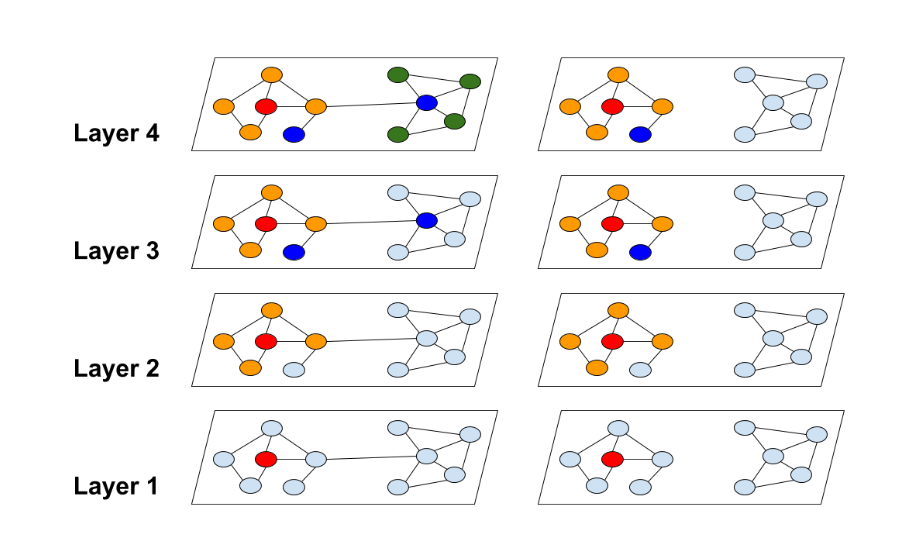
利用李宏毅老师助教讲解的GNN时的PPT可以区分aggregate和readout:
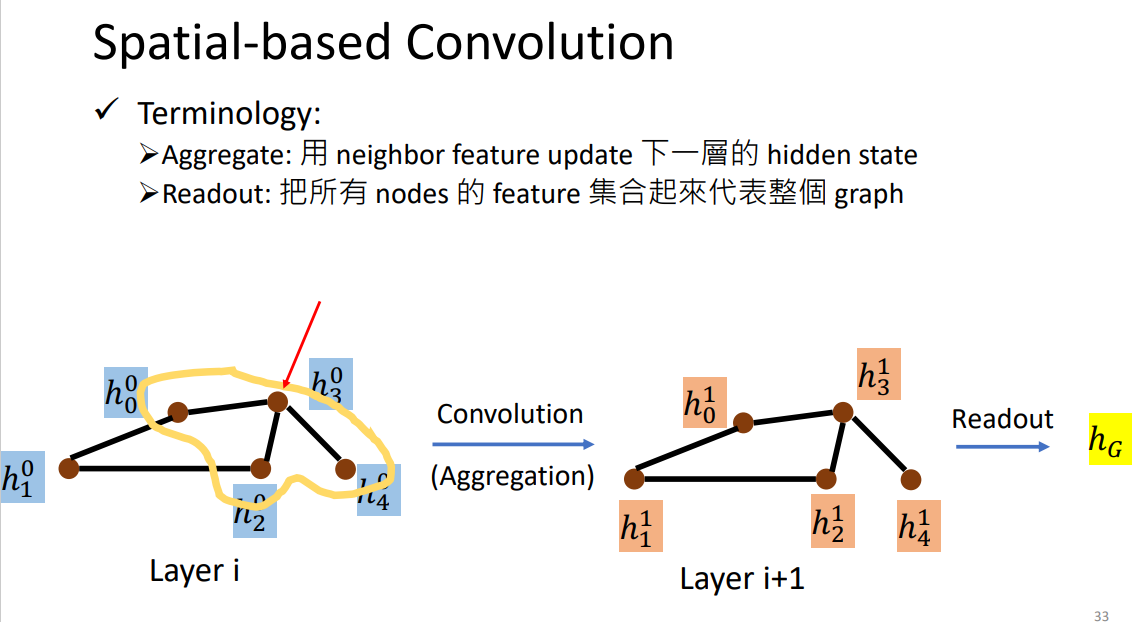
总的来说,基于消息传递图神经网络框架设计的图神经网络模型,就是通过设计不同的消息函数、更新函数、以及读出函数实现的,从而利用不同的方式聚合自身和邻居特征,且得到整个图的特征。
接下来详细说明这个框架的两个阶段及包含的三个核心函数。
1、消息传递阶段(message passing phase)
在消息传递阶段,对于一个特定的节点v,包括聚合邻居特征(消息)和更新自身节点特征两个核心的部分,分别通过消息传递函数和节点更新函数实现。
解决的问题:目标节点不同层(或者说不同时间步)的邻居节点是如何影响目标节点的?换句话说,目标节点能从不同层的邻居节点学习到什么特征?
(1) 消息函数\(M_t\):聚合邻居特征(消息)
消息函数用于聚合目标节点的邻居特征,包括目标节点的自身特征\(h^{t}_v\)、其邻居节点特征\(h_{w}^{t}\)、其与邻居节点链接的连边特征\(e_{vw}\) ,进而形成一个消息向量\(m_{v}^{t+1}\)传递给目标节点,公式如下: \[ \begin{array}{c} m_{v}^{t+1}=\sum_{w \in N(v)} M_{t}\left(h_{v}^{t}, h_{w}^{t}, e_{v w}\right) \\ \end{array} \] 其中,\(m_{v}^{t+1}\)为节点\(v\)在第\((t+1)\)层接收到的信息,\(M_t\)为消息函数,\(h^{t}_v\)表示第\((t)\)层中节点\(v\)的节点特征,\(N(v)\)表示节点\(v\)的邻居节点集合, \(h_{w}^{t}\)表示第\((t)\)层中节点\(v\)的邻居节点\(w\)的节点特征,\(e_{vw}\) 表示从节点\(v\)到节点\(w\)的边的特征。
(2) 节点更新函数\(U_{t}\):更新自身节点特征
节点更新函数用于更新下一层节点的节点特征\(h_{v}^{t+1}\),组合了当前层节点的特征\(h_{v}^{t}\)以及从消息函数中获得的消息\(m_{v}^{t+1}\),公式如下: \[ h_{v}^{t+1}=U_{t}\left(h_{v}^{t}, m_{v}^{t+1}\right) \] 其中,\(U_{t}\)是节点更新函数,该函数把原节点状态\(h_{v}^{t}\)和消息\(m_{v}^{t+1}\)作为输入,得到新的节点状态\(h_{v}^{t+1}\)。
(3) 举个例子
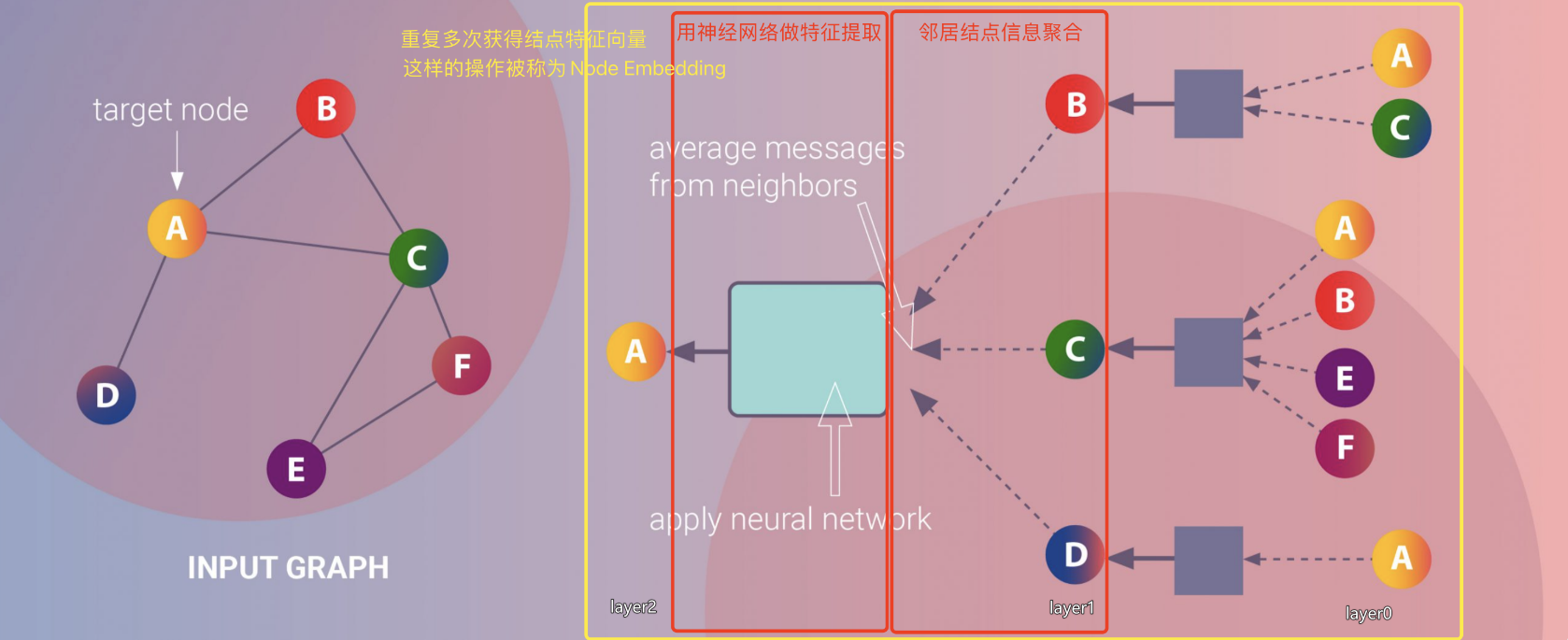
下图左侧为输入的网络,节点A为目标节点。以两层的消息传递过程为例说明目标节点A的消息传递过程。
目标节点为A,我们要通过消息传递将邻居特征一层一层传递到目标节点A处。
1步层:节点A经1步可到达的节点集合为{B,C,D},A-B,A-C,A-D;
2步层:节点A经过节点B经2步可到达的节点集合为{A,C},A-B-A,A-B-C;
节点A经过节点C经2步可到达的节点集合为{A,B,E,F},A-C-A,A-C-B,A-C-E,A-C-F;
节点A经过节点D经2步可到达的节点集合为{A},A-D-A;
我们将最远层(此处为2步层)的节点集合作为Layer0,通过消息函数聚合到Layer1,再通过消息函数聚合到Layer2,以此类推,最终将消息聚合到目标节点LayerN(此处为Layer2);
然后利用节点更新函数结合自身节点特征和消息进行自身节点特征更新,完成节点A的消息传递过程。
(4) 实例模型中的消息传递(主要摘自理解Graph Neural Networks 消息传递机制——多篇论文图神经网络消息传递框架对比)
- 一些模型中使用的消息函数对比
- Every Document Owns Its Structure: Inductive Text Classification via Graph Neural Networks
img 这是最原始的方法,直接将邻接矩阵与节点特征矩阵相乘,物理意义就是将所有邻居特征求和(sum)。
- Message Passing Attention Networks for Document Understanding
img 针对邻居信息求和后的结果,送入多层感知机,获得更抽象的特征表示。
- HOW POWERFUL ARE GRAPH NEURAL NETWORKS? (Aggregation Function+Combination Function)
img 论文将聚合函数和组合函数写在一个式子中了,最右边就是聚合函数,也是对所有邻居信息求和。
小结:通过对比发现,聚合函数一般情况下是对所有的邻居节点信息sum起来,如果想获得更高阶的表示,可以再次送入神经网络学习。在sum过程中也可以考虑不同节点的权重,像GAT一样进行加权求和。
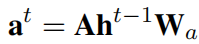
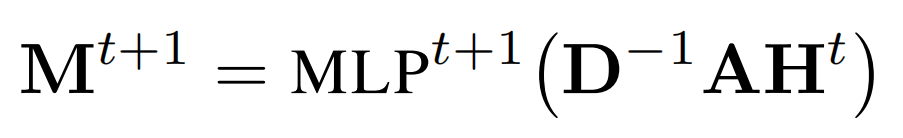
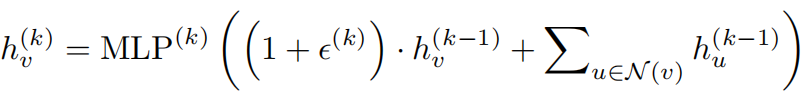
一些模型中使用的更新函数对比
GRU-based模型可以用作函数更新(如以下的1和2)
- Every Document Owns Its Structure: Inductive Text Classification via Graph Neural Networks
img 组合函数使用门控单元,由于我们的目标是将邻居信息和节点本身信息组合起来,因此通过重置门、更新门控制邻居信息在节点更新过程中的贡献度是多大。
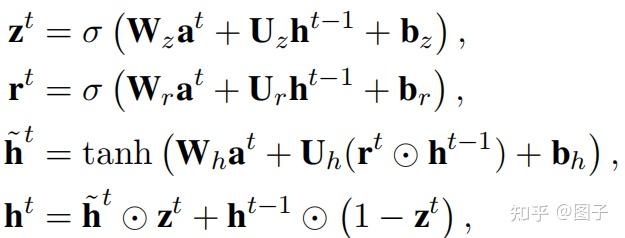
其中,σ是 sigmoid 函数, \(\mathbf{W}\)、 \(\mathbf{U}\)和 $ $ 是可训练的权重和偏置. $ $ 和\(\mathbf{r}\)分别是更新门和重置门,以确定邻居信息在多大程度上用于当前节点嵌入。(摘自:【论文笔记】Every Document Owns Its Structure: Inductive Text Classification via Graph Neural Networks)
TextING-Graph-based Word Interaction
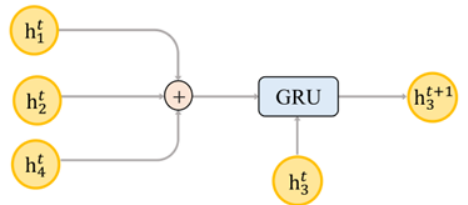
- Message Passing Attention Networks for Document Understanding
img 同上。
- HOW POWERFUL ARE GRAPH NEURAL NETWORKS?
img 式子中ϵ 是可学习的参数或者标量,能够灵活的建模邻居节点和当前节点的交互,最外层使用多层感知机拟合任意函数。
小结:由于组合函数面临两方面的信息,即节点自身信息和邻居信息,因此如何对这两方面信息进行一个tradeoff是非常重要的,在此我列举的论文是通过门机制和设置可学习参数来实现。
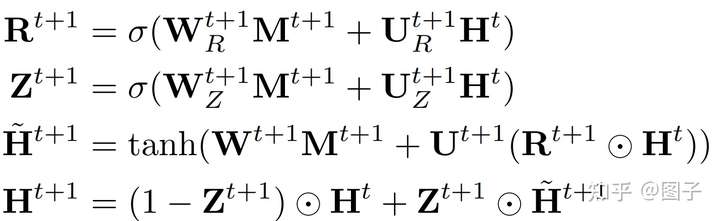
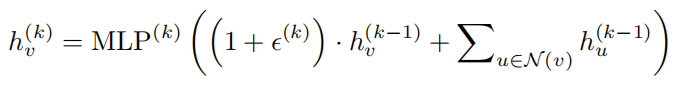
2、读出阶段(readout phase)
对于图级别的任务(如图分类)仅仅获得节点级别的表示是不够的,对节点级别的表示进行readout,获得图级别的表示。
(1) 读出函数\(R\):获得图特征
使用读出函数\(R\)计算整张图的特征向量,公式如下: \[ \hat{y}=R\left(\left\{h_{v}^{T} \mid v \in G\right\}\right) \] 其中\(\hat{y}\)为最终输出的向量,\(R\)是读出函数,该函数需要满足两个要求1)可求导;2)满足置换不变性(结点的输入顺序不改变最终结果,这也是为了保证MPNN对图的同构有不变性)。
(2) 实例模型中的读出函数(摘自理解Graph Neural Networks 消息传递机制——多篇论文图神经网络消息传递框架对比)
一些模型中使用的readout函数对比:
- Every Document Owns Its Structure: Inductive Text Classification via Graph Neural Networks
img 首先对节点特征变换:输入每个节点特征,第一项是soft attention weight,第二项是non-linear feature transformation。随后,聚合节点特征与重要的邻居节点特征,在对图中所有节点求平均的基础上,又使用maxpooling捕获了文本中的关键词信息。
- Message Passing Attention Networks for Document Understanding
img 在读出函数中运用了自注意力机制,认为每一个节点对于最终的图表示的贡献程度不同,对图中节点表示进行加权求和,得到注意力向量。
- HOW POWERFUL ARE GRAPH NEURAL NETWORKS?
img 不是单纯的readout最后一层的节点表示,而是把每一层的节点更新的表示结果拼接起来,防止网络层之间的信息流失。
小结:读出过程的目标就是聚集所有的节点信息,那么在具体任务中,我们要明确的是哪些节点更为有价值,想办法让它们贡献的更多(attention机制)。
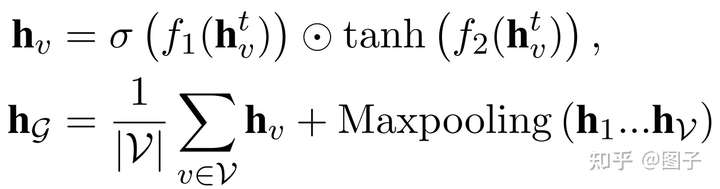
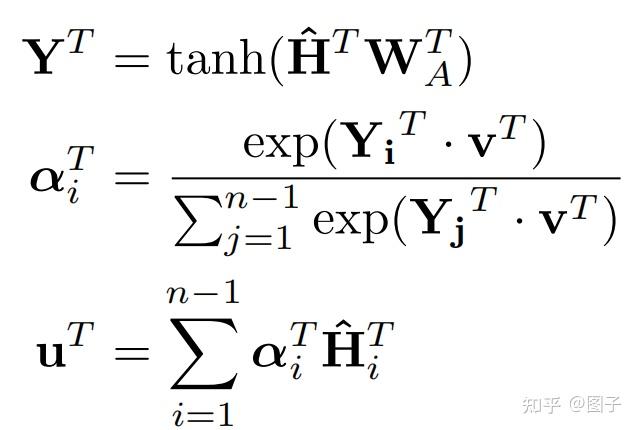
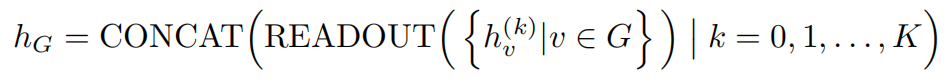
三、代码框架
结合两个案例分别说明如何基于该框架进行模型设计,一个是GCN,该模型只使用了消息传递策略,不需要读出阶段,可以使用torch_geometric.nn.MessagePassing来进行设计;另一个模型为TextING,该模型包括了消息传递阶段和读出阶段。
1、在GCN(Graph Convolutional Network)层中使用消息传递策略
(1) GCNconv原理
相邻节点的特征首先通过权重矩阵\(\mathbf{\Theta}\)进行转换,然后按端点的度进行归一化处理,最后进行加总。 \[ \mathbf{x}_{i}^{(k)}=\sum_{j \in \mathcal{N}(i) \cup\{i\}} \frac{1}{\sqrt{\operatorname{deg}(i)} \cdot \sqrt{\operatorname{deg}(j)}} \cdot\left(\boldsymbol{\Theta} \cdot \mathbf{x}_{j}^{(k-1)}\right) \]
(2) 6个步骤实现GCN的消息传递过程
向邻接矩阵添加自环边。(邻接矩阵+I)
线性转换节点特征矩阵。
计算归一化系数。
归一化\(j\)中的节点特征。
将相邻节点特征以一定方式聚合(如相加、最大值、平均等)。
更新节点新的embeddings 。
其中,1-3是在消息传递发生之前,4-6可以用torch_geometric.nn.MessagePassing来进行设计。
(3) 基于torch_geometric.nn.MessagePassing设计GCNconv-代码
import torch |
可以把这个GCNconv层作为深度架构的构建块,进一步搭建模型。
conv = GCNConv(16, 32) |
2、TextING
看了一些模型的源码,许多模型会将模型和传递层分开不同类定义,并在模型类的初始化函数中初始化各个层,然后在该类的forward()函数中定义前向传播方式。也就是说MPNN模型往往可以拆分为以下几个部分(截取自TextING源码TextING-pytorch):
class GraphLayer(nn.Module): |
四、参考文献
[论文原文:Neural Message Passing for Quantum Chemistry]
理解Graph Neural Networks 消息传递机制——多篇论文图神经网络消息传递框架对比
torch_geometric.nn.MessagePassing
【论文笔记】Every Document Owns Its Structure: Inductive Text Classification via Graph Neural Networks