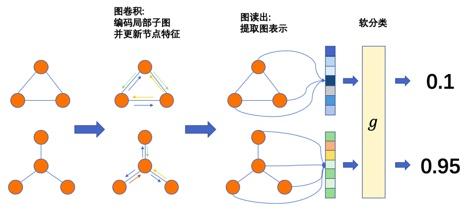
图神经网络的下游任务3-图分类
引言
在之前已经知道如何利用图神经网络进行图级别的表示学习 。利用GNN学习到的图表示,我们可以进行第三类下游任务——图分类。这与节点分类的道理是类似的。
在这篇博客中,我们将首先介绍图分类任务,借助这个下游任务,学习如何在pytorch和PyG的DataLoader类实现mini-batch,并补充几个编写GNN或者其他深度学习代码常用的步骤。
看完以后可以掌握以下内容:
使用pytorch和PyG批量化处理大小各异的图数据;
利用图神经网络实现图分类任务;
完整的利用GNN进行下游任务的代码框架,包括:
DataLoader实现mini-batch;
日志文件、可视化;
scheduler管理optimizer;
模型的保存和断点继续训练;
模型预测。
图分类概述
图分类定义
图分类其实和节点分类相似,本质就是预测图的标签。根据图的特征(比如图密度、图拓扑信息等)、已知图的标签,对未知标签的图做类别预测。
图分类应用意义
它的应用广泛,可见于生物信息学、化学信息学、社交网络分析、城市计算以及网络安全。随着近来学界对于图神经网络的热情持续高涨,出现了一批用图神经网络做图分类的工作。比如训练图神经网络来预测蛋白质结构的性质,根据社交网络结构来预测用户的所属社区等。
DataLoader实现mini-batch
创建mini-batch处理对于让深度学习模型的训练规模适应海量数据至关重要。mini-batch不是逐个处理样本,而是将一组样本分组成统一的表示形式,以高效地并行处理。在图像或语言领域中,这个过程通常是通过将每个样本重新缩放或填充成一组大小相同的形状来实现的,然后将样本分组到一个额外的维度中。这个维度的长度等于一个小批处理中分组的样本的数量,通常称为batch_size。
有两种方式可以实现mini-batch:
Pytorch的DataLoader
自定义一个继承 Dataset类的类 ,需要重写以下三个函数:
__init__:传入数据,或者像下面一样直接在函数里加载数据;__len__:返回这个数据集一共有多少个item;__getitem__:返回一条训练数据,并将其转换成tensor。通常还会在其中增加一个collate_fn函数,用于DataLoader,使用这个参数可以自己操作每个batch的数据,比如说在自然语言处理的命名实体识别任务中,在该函数中对每个batch中的样本都padding到同一长度等。
import torchfrom torch.utils.data import Datasetclass Mydata (Dataset ): def __init__ (self ): a = np.load("a.npy" ,allow_pickle=True ) b = np.load("b.npy" ,allow_pickle=True ) d = np.load("d.npy" ,allow_pickle=True ) c = np.load("c.npy" ) self.x = list (zip (a,b,d,c)) def __getitem__ (self, idx ): assert idx < len (self.x) return self.x[idx] def __len__ (self ): return len (self.x) def collate_fn (self,batch ): pass
Pytorch的DataLoader包括三个参数:
dataset:传入的数据;shuffle = True:是否打乱数据;collate_fn函数:使用这个参数可以自己操作每个batch的数据。
dataset = Mydata() dataloader = DataLoader(dataset, batch_size = 2 , shuffle=True ,collate_fn = dataset.collate_fn)
PyG的DataLoader
torch_geometric.data.DataLoaderDataLoader的子类,它覆盖了collate()函数,该函数定义了一列表的样本是如何封装成批的。因此,所有可以传递给PyTorch DataLoader的参数也可以传递给PyTorch Geometric的 DataLoader,例如,num_workers。通过torch_geometric.data.DataLoader
DataLoader的默认处理方式
将小图存储到大图中时需要对小图的属性做一些修改,一个最显著的例子就是要对节点序号增值。在最一般的形式中,PyTorch Geometric的DataLoader类会自动对edge_index张量增值,增加的值为当前被处理图的前面的图的累积节点数量。比方说,现在对第\(k\) 个图的edge_index张量做增值,前面\(k-1\) 个图的累积节点数量为\(n\) ,那么对第\(k\) 个图的edge_index张量的增值\(n\) 。增值后,对所有图的edge_index张量(其形状为[2, num_edges])在第二维中连接起来。
在未做修改的情况下,它们在Data
def __inc__ (self, key, value ): if 'index' in key or 'face' in key: return self.num_nodes else : return 0 def __cat_dim__ (self, key, value ): if 'index' in key or 'face' in key: return 1 else : return 0
我们可以看到,__inc__()定义了两个连续的图的属性之间的增量大小,而__cat_dim__()定义了同一属性的图形张量应该在哪个维度上被连接起来。PyTorch Geometric为存储在Datakey和值value作为参数。
在一些场景下可以通过重写torch_geometric.data.__inc__()torch_geometric.data.__cat_dim__()
图匹配(Pairs of Graphs)
如果你想在一个Data\(G_s\) 和一个目标图\(G_t\) ,存储在一个Data
class PairData (Data ): def __init__ (self, edge_index_s, x_s, edge_index_t, x_t ): super (PairData, self).__init__() self.edge_index_s = edge_index_s self.x_s = x_s self.edge_index_t = edge_index_t self.x_t = x_t
在这种情况中,edge_index_s应该根据源图\(G_s\) 的节点数做增值,即x_s.size(0),而edge_index_t应该根据目标图\(G_t\) 的节点数做增值,即x_t.size(0)。
class PairData (Data ): def __init__ (self, edge_index_s, x_s, edge_index_t, x_t ): super (PairData, self).__init__() self.edge_index_s = edge_index_s self.x_s = x_s self.edge_index_t = edge_index_t self.x_t = x_t def __inc__ (self, key, value ): if key == 'edge_index_s' : return self.x_s.size(0 ) if key == 'edge_index_t' : return self.x_t.size(0 ) else : return super ().__inc__(key, value)
可以通过一个简单的测试脚本来测试我们的PairData批处理行为。
edge_index_s = torch.tensor([ [0 , 0 , 0 , 0 ], [1 , 2 , 3 , 4 ], ]) x_s = torch.randn(5 , 16 ) edge_index_t = torch.tensor([ [0 , 0 , 0 ], [1 , 2 , 3 ], ]) x_t = torch.randn(4 , 16 ) data = PairData(edge_index_s, x_s, edge_index_t, x_t) data_list = [data, data] loader = DataLoader(data_list, batch_size=2 ) batch = next (iter (loader)) print (batch)print (batch.edge_index_s)print (batch.edge_index_t)
edge_index_s和edge_index_t被正确地封装成batch了,即使在为\(G_s\) 和\(G_t\) 含有不同数量的节点时也是如此。然而,由于PyTorch Geometric无法识别PairData对象中实际的图,所以batch属性(将大图每个节点映射到其各自对应的小图)没有正确工作。此时就需要DataLoaderfollow_batch参数发挥作用 。在这里,我们可以指定我们要为哪些属性维护批信息。
loader = DataLoader(data_list, batch_size=2 , follow_batch=['x_s' , 'x_t' ]) batch = next (iter (loader)) print (batch)print (batch.x_s_batch)print (batch.x_t_batch)
可以看到,follow_batch=['x_s', 'x_t']现在成功地为节点特征x_s'和x_t'分别创建了名为x_s_batch和x_t_batch的赋值向量。这些信息现在可以用来在一个单一的Batch对象中对多个图进行聚合操作,例如,全局池化。
二部图(Bipartite Graphs)
二部图的邻接矩阵定义两种类型的节点之间的连接关系。一般来说,不同类型的节点数量不需要一致,于是二部图的邻接矩阵\(A \in \{0,1\}^{N \times M}\) 可能为平方矩阵,即可能有\(N \neq M\) 。对二部图的封装成批过程中,edge_index 中边的源节点与目标节点做的增值操作应是不同的。 将二部图中两类节点的特征特征张量分别存储为x_s和x_t。
class BipartiteData (Data ): def __init__ (self, edge_index, x_s, x_t ): super (BipartiteData, self).__init__() self.edge_index = edge_index self.x_s = x_s self.x_t = x_t
为了对二部图实现正确的封装成批,需要告诉PyG,它应该在edge_index中独立地为边的源节点和目标节点做增值操作。
def __inc__ (self, key, value ): if key == 'edge_index' : return torch.tensor([[self.x_s.size(0 )], [self.x_t.size(0 )]]) else : return super ().__inc__(key, value)
其中,edge_index[0](边的源节点)根据x_s.size(0)做增值运算,而edge_index[1](边的目标节点)根据x_t.size(0)做增值运算
通过运行一个简单的脚本来测试:
edge_index = torch.tensor([ [0 , 0 , 1 , 1 ], [0 , 1 , 1 , 2 ], ]) x_s = torch.randn(2 , 16 ) x_t = torch.randn(3 , 16 ) data = BipartiteData(edge_index, x_s, x_t) data_list = [data, data] loader = DataLoader(data_list, batch_size=2 ) batch = next (iter (loader)) print (batch)print (batch.edge_index)
利用图神经网络进行图分类
接下来我们将以数据集为例,编写一个Dataset类,然后利用DataLoader加载数据集;接着根据中的所设计的GIN网络学习各个小图的表征,并在图网络的最后一层接入分类层,对小图进行分类;最后对模型性能进行测试。结构如下图所示:
图分类模型示意
数据集介绍
加载数据
ogbg-molhiv 是一个分子性质预测数据集,它包含了41,127个图。
注意以下代码依赖于ogb包,通过pip install ogb命令可安装此包。ogb文档可见于Get Started | Open Graph Benchmark (stanford.edu) 。
数据集加载如下:
from ogb.graphproppred.dataset_pyg import PygGraphPropPredDatasetdataset = PygGraphPropPredDataset(name = 'ogbg-molhiv' ) split_idx = dataset.get_idx_split() train_data = dataset[split_idx['train' ]] valid_data = dataset[split_idx['valid' ]] test_data = dataset[split_idx['test' ]]
DataLoader实现mini-batch
在生成一个DataLoader变量时,通过指定num_workers可以实现并行 执行生成多个图。
train_loader = DataLoader(train_data, batch_size=args.batch_size, shuffle=True , num_workers=args.num_workers) valid_loader = DataLoader(valid_data, batch_size=args.batch_size, shuffle=False , num_workers=args.num_workers) test_loader = DataLoader(test_data, batch_size=args.batch_size, shuffle=False , num_workers=args.num_workers)
实验
借助这份代码,我们再梳理以下几个知识点,为了编写更完整的运行流程代码。
设计Net
详细的Net介绍见GIN:逼近WL-test的GNN架构 | 冬于的博客 (ifwind.github.io) 。
其中self.graph_pred_linear函数用于预测图标签。
选择优化器和loss function
在选择优化器后,可以利用lr_scheduler 学习率调整策略来调整优化器的学习率。
具体可以参考torch.optim.lr_scheduler:调整学习率 写的非常好。
import torch.optim as optimfrom torch.optim.lr_scheduler import StepLRoptimizer = optim.Adam(model.parameters(), lr=0.001 ,weight_decay=args.weight_decay) scheduler = StepLR(optimizer, step_size=30 , gamma=0.25 )
输出训练日志
此外,我们在训练模型的过程中,使用的超参数以及模型训练过程中的loss、评价指标等都应进行实时记录,这对模型的复现和调参都很有帮助。
记录超参数等训练信息可以使用以下方式:
args.output_file = open (os.path.join(args.save_dir, 'output' ), 'a' ) num_params = sum (p.numel() for p in model.parameters()) print (f'#Params: {num_params} ' , file=args.output_file, flush=True )print (model, file=args.output_file, flush=True )print (args, file=args.output_file, flush=True )print ("=====Epoch {}" .format (epoch), file=args.output_file, flush=True )print ('Training...' , file=args.output_file, flush=True )print ({'Train' : train_mae, 'Validation' : valid_mae}, file=args.output_file, flush=True )args.output_file.close()
针对评价指标和loss的可视化可以使用summaryWriter :
writer = SummaryWriter(log_dir=args.save_dir) writer.add_scalar('valid/mae' , valid_mae, epoch) writer.add_scalar('train/mae' , train_mae, epoch) writer.close()
在控制面板中输入:
tensorboard --logdir=logfilename
进入链接(TensorBoard 2.4.1 at http://localhost:port/)可查看summaryWriter结果。
训练
def train (model, device, loader, optimizer,scheduler, criterion_fn ): model.train() loss_accum = 0 for step, batch in enumerate (tqdm(loader)): batch = batch.to(device) pred = model(batch).view(-1 ,) optimizer.zero_grad() loss = criterion_fn(pred, batch.y) loss.backward() optimizer.step() scheduler.step() loss_accum += loss.detach().cpu().item() return loss_accum / (step + 1 )
验证
def eval (model, device, loader, evaluator ): model.eval () y_true = [] y_pred = [] with torch.no_grad(): for _, batch in enumerate (tqdm(loader)): batch = batch.to(device) pred = model(batch).view(-1 ,) y_true.append(batch.y.view(pred.shape).detach().cpu()) y_pred.append(pred.detach().cpu()) y_true = torch.cat(y_true, dim=0 ) y_pred = torch.cat(y_pred, dim=0 ) input_dict = {"y_true" : y_true, "y_pred" : y_pred} return evaluator.eval (input_dict)["mae" ]
模型保存和断点继续训练
在训练模型过程中,对模型进行保存是很重要的。
核心包括两个内容:
最优模型保存机制;
如何从断点加载模型继续训练。
最优模型通常通过设置测试间隔,根据选定的指标,选择训练过程中表现最优的模型进行保存。需要保存以下内容到checkpoint:
核心:模型参数、优化器参数、scheduler参数;
其他:训练epoch、模型超参数、模型评价指标。
只保存和加载模型的话,还有其他方式可参考:PyTorch之保存加载模型 - 简书 (jianshu.com)
checkpoint = { 'model_state_dict' : model.state_dict(), 'optimizer_state_dict' : optimizer.state_dict(), 'scheduler_state_dict' : scheduler.state_dict(), 'epoch' : epoch, 'best_val_mae' : best_valid_mae, 'num_params' : num_params } torch.save(checkpoint, os.path.join(args.save_dir, 'checkpoint.pt' ))
要实现断点继续训练只需要将模型上次保存的checkpoint加载进来,然后继续训练即可:
path_checkpoint = "./model_parameter/test/ckpt_best_50.pth" checkpoint = torch.load(path_checkpoint) model = TheModelClass(*args, **kwargs) optimizer = TheOptimizerClass(*args, **kwargs) lr_schedule = ThelrscheduleClass(*args, **kwargs) model.load_state_dict(checkpoint['model_state_dict' ]) optimizer.load_state_dict(checkpoint['optimizer' ]) start_epoch = checkpoint['epoch' ] lr_schedule.load_state_dict(checkpoint['lr_schedule' ]) for epoch in range (start_epoch, args.epochs + 1 ): train_mae = train(model, device, train_loader, optimizer,scheduler, criterion_fn)
模型预测和保存预测结果
最后,当我们要利用模型进行最终的预测时(此时不需要输入target参数),或者有的时候可以在模型中单独写一个inference()推断函数加快预测速度,如链路预测 中的编写inference()的案例:
def predict (model, device, loader ): model.eval () y_pred = [] with torch.no_grad(): for _, batch in enumerate (loader): batch = batch.to(device) pred = model(batch).view(-1 ,) y_pred.append(pred.detach().cpu()) y_pred = torch.cat(y_pred, dim=0 ) return y_pred def predict_inference (model, device, loader ): model.eval () y_pred = [] with torch.no_grad(): for _, batch in enumerate (loader): batch = batch.to(device) pred = model.inference(batch).view(-1 ,) y_pred.append(pred.detach().cpu()) y_pred = torch.cat(y_pred, dim=0 ) return y_pred def save_test_submission (self, input_dict, dir_path ): ''' save test submission file at dir_path ''' assert ('y_pred' in input_dict) y_pred = input_dict['y_pred' ] if not osp.exists(dir_path): os.makedirs(dir_path) filename = osp.join(dir_path, 'y_pred' ) assert (isinstance (filename, str )) if isinstance (y_pred, torch.Tensor): y_pred = y_pred.numpy() y_pred = y_pred.astype(np.float32) np.savez_compressed(filename, y_pred=y_pred) path_checkpoint = "./model_parameter/test/ckpt_best_50.pth" checkpoint = torch.load(path_checkpoint) model = TheModelClass(*args, **kwargs) model.load_state_dict(checkpoint['model_state_dict' ]) y_pred=predict(model, device, loader) save_test_submission({'y_pred' : y_pred}, args.save_dir)
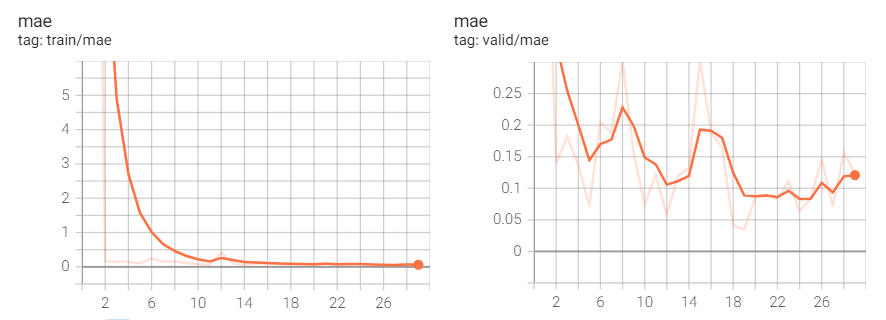
实验结果
训练结束后,查看summaryWriter结果如下:
完整代码
Task9-graph_classification
参考文献
9-1-按需获取的数据集类的创建.md
ADVANCED MINI-BATCHING
专栏 | 手把手教你用DGL框架进行批量图分类
GIN:逼近WL-test的GNN架构 | 冬于的博客 (ifwind.github.io)
torch.optim.lr_scheduler:调整学习率
PyTorch实现断点继续训练
Pytorch(五)入门:DataLoader 和 Dataset
Pytorch中DataLoader的使用