BERT相关——(3)BERT模型
BERT相关——(3)BERT模型
引言
BERT是一种基于微调的多层双向Transformer编码器,但实际上BERT只包括了Transformer的Encoder结构。
BERT
BERT模型结构
BERT输入与原始Transformer类似(input embedding和position encoding结合),然后进入由多个Encoder堆叠而成的Encoder堆栈;最后进行输出。
BERT有两个版本的BERT模型,在两个版本中前馈大小都设置为4层:
- BERT BASE:L=12,H=768,A=12,Total Parameters=110M
- BERT LARGE:L=24,H=1024,A=16,Total Parameters=340M
其中层数(即Transformer blocks块)表示为L,隐藏大小表示为H,自注意力的数量为A。
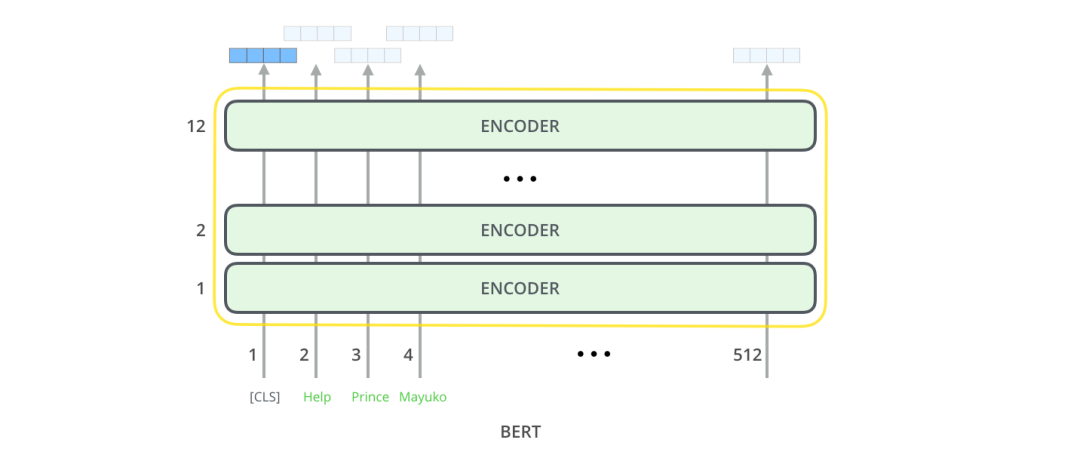
BERT设计了两种方式来更好地学习Contextualized Word Embedding。
Masked Language Model(MLM 语言模型)
Encoder中的Self Attention 层,每个 token 会把大部分注意力集中到自己身上,这样将容易预测到每个 token,模型学不到有用的信息。
找到合适的任务来训练一个 Transformer 的 Encoder 是一个复杂的问题,BERT 在语言建模任务中,使用早期文献中的"masked language model"概念(在这里被称为完形填空),巧妙地屏蔽了输入中 15% 的单词,并让模型预测这些屏蔽位置的单词。以此解决这个问题。
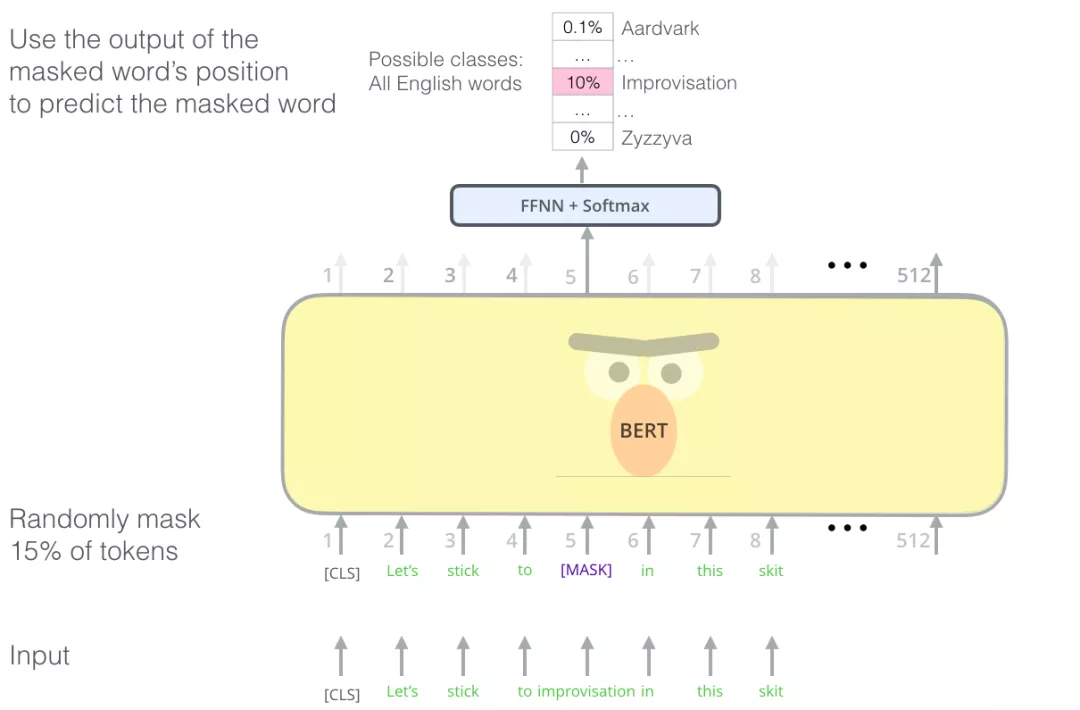
除了屏蔽输入中 15% 的单词外, BERT 还混合使用了其他的一些技巧,例如,有时它会随机地用一个词替换另一个词,然后让模型预测这个位置原来的实际单词。
Next Sentence Prediction
很多句子级别的任务如自动问答(QA)和自然语言推理(NLI)都需要理解两个句子之间的关系。
因此为了让 BERT 更好地处理多个句子之间的关系,预训练过程还包括一个额外的任务:给出两个句子(A 和 B),判断 B 是否是 A 后面的相邻句子。
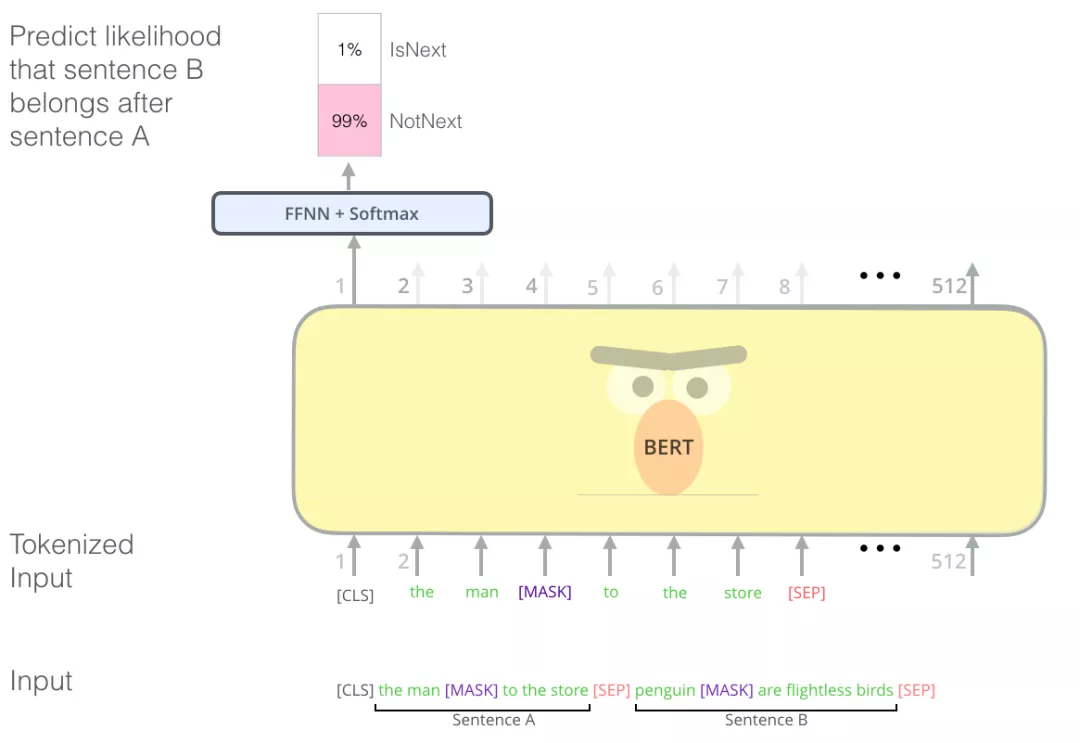
Next Sentence Prediction任务随机将数据划分为等大小的两部分,一部分数据中的两个语句对是上下文连续的,另一部分数据中的两个语句对是上下文不连续的。然后让Transformer模型来识别这些语句对中,哪些语句对是连续的,哪些对子不连续。
positional encoding
最后训练好的BERT模型两个权重矩阵:token encodings和positional encodings,也就是说positional encodings是随着网络一起训练的。positional encoding参考之前写的博客:Transformer相关——(4)Poisition encoding。
BERT Layer
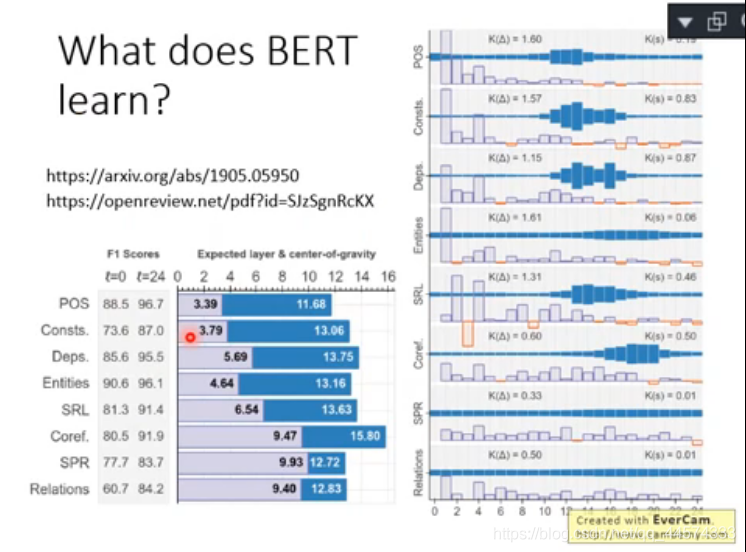
与ELMO相同,BERT也有很多层,那每一层到底都学到了什么呢?
BERT的每一层做的像是NLP各个任务的pipeline,且层由浅入深其代表的NLP任务越来越复杂。
举例来说,如上图BERT有24层,所以每个词汇有24个vector,把这些vector乘上对应的权重参数加权求和得到最终词汇的embedding。
上图右侧就是把BERT的每一层的权重参数提取出来,深蓝色的方块就是权重参数。可以看到对于POS词性标注任务,第10-12层的权重参数更大,表示这几层对于POS来说是更重要的。而困难一些的NLP任务可以看到后面几层的权重参数更大,这也就体现了BERT对于语言模型的理解能力,由浅入深,由简至难。