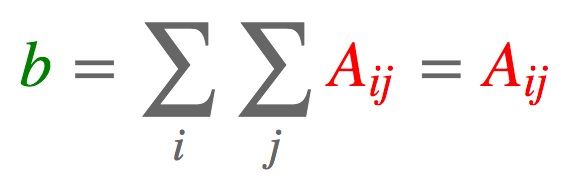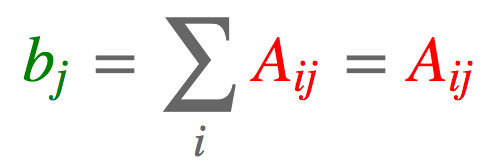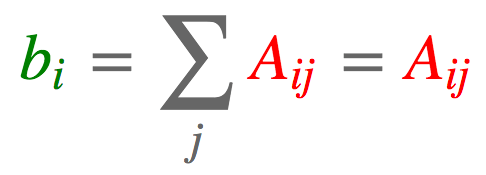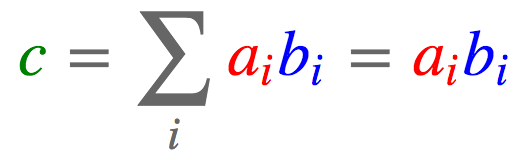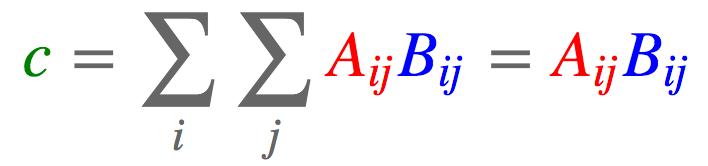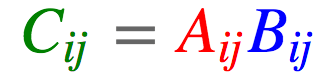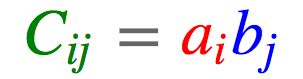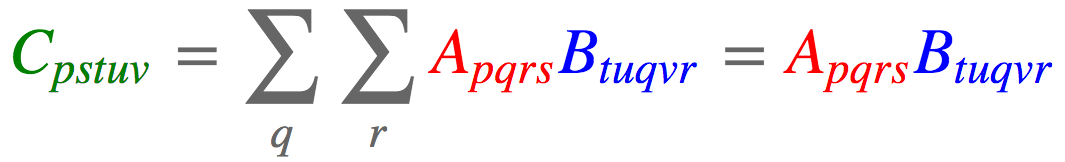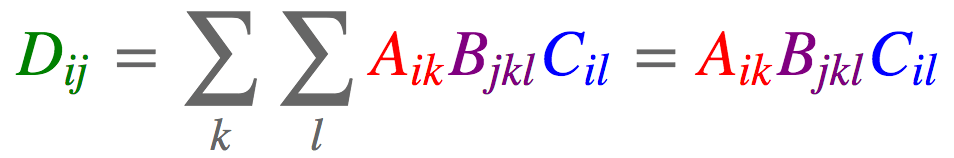Pytorch与深度学习自查手册1-张量、自动求导和GPU
张量
构造Tensor
dtype类型:dtype=torch.long,torch.float,torch.double
常见的构造Tensor的函数:
Tensor(sizes )
基础构造函数
torch.Tensor(4,3)
tensor(data )
类似于np.array
x = torch.tensor([5.5, 3])
ones(sizes )
全1
zeros(sizes )
全0
x = torch.zeros(4, 3, dtype=torch.long )
eye(sizes )
对角为1,其余为0
arange(s,e,step )
从s到e,步长为step
linspace(s,e,steps )
从s到e,均匀分成step份
rand/randn(sizes )
x = torch.rand(4, 3)
normal(mean,std )/uniform(from,to )
正态分布/均匀分布
empty(sizes )
result = torch.empty(5, 3) torch.add(x, y, out=result)
基本属性
常用方法
改变一个 tensor 的大小或者形状,可以使用 torch.view:view() 返回的新tensor 与源tensor 共享内存(其实是同一个tensor ),也即更改其中的一个,另 外一个也会跟着改变。
x = torch.randn(4 , 4 ) y = x.view(16 ) z = x.view(-1 , 8 )
转置transpose/维度交换permute
x=torch.randn(2,4,3) s=x.transpose(1,2) #shape=[2,3,4] z=x.permute(0,2,1) #shape=[2,3,4]
扩展expand
#返回当前张量在某个维度为1扩展为更大的张量 x = torch.Tensor([[1], [2], [3]])#shape=[3,1] t=x.expand(3, 4) print(t) ''' tensor([[1., 1., 1., 1.], [2., 2., 2., 2.], [3., 3., 3., 3.]]) '''
重复repeat
#沿着特定的维度重复这个张量 x=torch.Tensor([[1,2,3]]) t=x.repeat(3, 2) print(t) ''' tensor([[1., 2., 3., 1., 2., 3.], [1., 2., 3., 1., 2., 3.], [1., 2., 3., 1., 2., 3.]]) '''
拼接cat
x = torch.randn(2,3,6) y = torch.randn(2,4,6) c=torch.cat((x,y),1) #c=(2*7*6)
堆叠stack
""" 而stack则会增加新的维度。 如对两个1*2维的tensor在第0个维度上stack,则会变为2*1*2的tensor;在第1个维度上stack,则会变为1*2*2的tensor。 """ a = torch.rand((1, 2)) b = torch.rand((1, 2)) c = torch.stack((a, b), 0)
压缩和扩展维度:改变tensor中只有1个维度的tensor
x = torch.Tensor(1,3) y=torch.squeeze(x, 0) # y=torch.unsqueeze(y, 1)
矩阵乘法
做矩阵a*b以下操作一样。
如果a是一个n×m张量,b是一个 m×p 张量,将会输出一个 n×p 张量c。
a = torch.rand(2 ,4 ) b = torch.rand(4 ,3 ) c = a.mm(b) c = torch.mm(a, b) c = torch.matmul(a, b) c = a @ b
.einsum()爱因斯坦求和约定
资料来自:einsum满足你一切需要:深度学习中的爱因斯坦求和约定
矩阵转置
import torch a = torch.arange(6).reshape(2, 3) torch.einsum('ij->ji', [a]) tensor([[ 0., 3.], [ 1., 4.], [ 2., 5.]])
求和
a = torch.arange(6).reshape(2, 3) torch.einsum('ij->', [a]) tensor(15.)
列求和
a = torch.arange(6).reshape(2, 3) torch.einsum('ij->j', [a]) tensor([ 3., 5., 7.])
行求和
a = torch.arange(6).reshape(2, 3) torch.einsum('ij->i', [a]) tensor([ 3., 12.])
矩阵-向量相乘
a = torch.arange(6).reshape(2, 3) b = torch.arange(3) torch.einsum('ik,k->i', [a, b]) tensor([ 5., 14.])
矩阵-矩阵相乘
a = torch.arange(6).reshape(2, 3) b = torch.arange(15).reshape(3, 5) torch.einsum('ik,kj->ij', [a, b]) tensor([[ 25., 28., 31., 34., 37.], [ 70., 82., 94., 106., 118.]])
点积 向量:
a = torch.arange(3) b = torch.arange(3,6) # [3, 4, 5] torch.einsum('i,i->', [a, b]) tensor(14.)
矩阵:
a = torch.arange(6).reshape(2, 3) b = torch.arange(6,12).reshape(2, 3) torch.einsum('ij,ij->', [a, b]) tensor(145.)
哈达玛积
a = torch.arange(6).reshape(2, 3) b = torch.arange(6,12).reshape(2, 3) torch.einsum('ij,ij->ij', [a, b]) tensor([[ 0., 7., 16.], [ 27., 40., 55.]])
外积
a = torch.arange(3) b = torch.arange(3,7) torch.einsum('i,j->ij', [a, b]) tensor([[ 0., 0., 0., 0.], [ 3., 4., 5., 6.], [ 6., 8., 10., 12.]])
batch矩阵相乘
a = torch.randn(3,2,5) b = torch.randn(3,5,3) torch.einsum('ijk,ikl->ijl', [a, b]) tensor([[[ 1.0886, 0.0214, 1.0690], [ 2.0626, 3.2655, -0.1465]], [[-6.9294, 0.7499, 1.2976], [ 4.2226, -4.5774, -4.8947]], [[-2.4289, -0.7804, 5.1385], [ 0.8003, 2.9425, 1.7338]]])
张量缩约 batch矩阵相乘是张量缩约 的一个特例。比方说,我们有两个张量,一个n阶张量
a = torch.randn(2,3,5,7) b = torch.randn(11,13,3,17,5) torch.einsum('pqrs,tuqvr->pstuv', [a, b]).shape torch.Size([2, 7, 11, 13, 17])
双线性变换 如前所述,einsum可用于超过两个张量的计算。这里举一个这方面的例子,双线性变换 。
a = torch.randn(2,3) b = torch.randn(5,3,7) c = torch.randn(2,7) torch.einsum('ik,jkl,il->ij', [a, b, c]) tensor([[ 3.8471, 4.7059, -3.0674, -3.2075, -5.2435], [-3.5961, -5.2622, -4.1195, 5.5899, 0.4632]])
pytorch自动求导机制及使用
pytorch自动求导机制
PyTorch 中autograd包为张量上的所有操作提供了自动求导机制。torch.Tensor是这个包的核心类。如果设置它的属性.requires_grad 为 True,那么它将会追踪对于该张量的所有操作。当完成计算后可以通过调用.backward(),来自动计算所有的梯度。这个张量的所有梯度将会自动累加到.grad属性。
举例
x = torch.arange(0 , 100 , 0.01 ,dtype=torch.double,requires_grad=True ) y = sum (10 * x + 5 ) y.backward() print (x.grad)
GPU配置
GPU的设置
os.environ['CUDA_VISIBLE_DEVICES' ] = '0,1' device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu" )
数据/模型拷贝到GPU上/拷贝到CPU上
ngpu=1 x.cuda() x.to(device) x.cpu() netG = model.to(device) if (device.type == 'cuda' ) and (ngpu > 1 ): netG = nn.DataParallel(netG, list (range (ngpu)))
随机种子设置
manualSeed = 999 print ("Random Seed: " , manualSeed)random.seed(manualSeed) torch.manual_seed(manualSeed)
参考资料
pytorch 中改变tensor维度(transpose)、拼接(cat)、压缩(squeeze)详解
einsum满足你一切需要:深度学习中的爱因斯坦求和约定
第二章 PyTorch基础知识/2.2 自动求导.md
PyTorch深度学习:60分钟入门(Translation)