Pytorch与视觉竞赛入门3.1-使用Pytorch搭建VGG
Pytorch与视觉竞赛入门3.1-使用Pytorch搭建VGG
VGG
原理
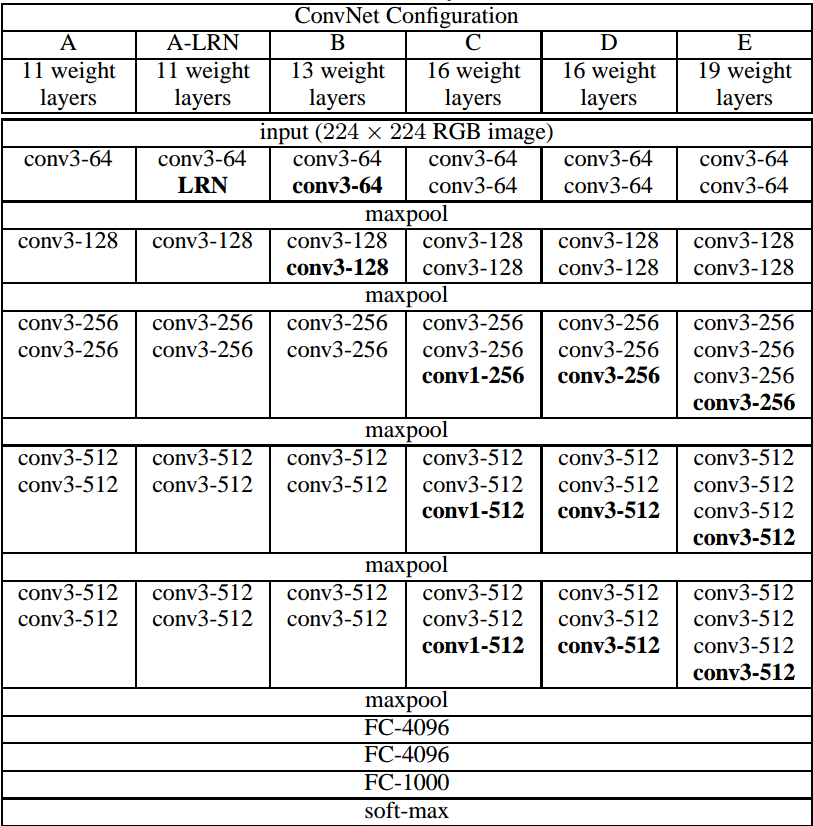
VGG16的结构图如下:
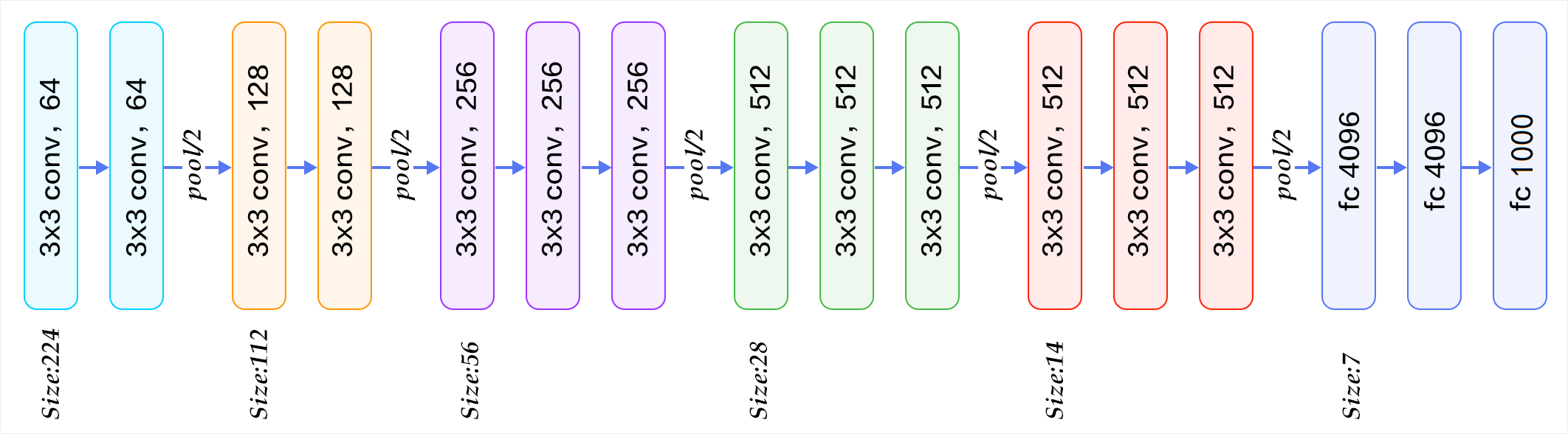
LRN模块
AlexNet中提出的局部响应归一化(LRN)(Krizhevsky等,2012),VGG的实验结果表明LRN对性能提升并没有什么帮助,而且还浪费了内存的计算的损耗。
特点
VGG16的突出特点是简单,体现在:
卷积层均采用相同的卷积核参数
卷积层均表示为
conv3-XXX,其中conv3说明该卷积层采用的卷积核的尺寸(kernel size)是3,即宽(width)和高(height)均为3,3*3是很小的卷积核尺寸,结合其它参数(步幅stride=1,填充方式padding=same),这样就能够使得每一个卷积层(张量)与前一层(张量)保持相同的宽和高。XXX代表卷积层的通道数。池化层均采用相同的池化核参数
池化层的参数均为2××2,步幅stride=2,max的池化方式,这样就能够使得每一个池化层(张量)的宽和高是前一层(张量)的1212。
模型是由若干卷积层和池化层堆叠(stack)的方式构成,比较容易形成较深的网络结构(在2014年,16层已经被认为很深了)。
综合上述分析,可以概括VGG的优点为: Small filters, Deeper networks.
VGG改进点总结
- 使用了更小的3*3卷积核,和更深的网络。两个3*3卷积核的堆叠相对于5*5卷积核的视野,三个3*3卷积核的堆叠相当于7*7卷积核的视野。这样一方面可以有更少的参数(3个堆叠的3*3结构只有7*7结构参数数量的\((3*3*3)/(7*7)=55\%\));另一方面拥有更多的非线性变换,增加了CNN对特征的学习能力。
- 在VGGNet的卷积结构中,引入1*1的卷积核,在不影响输入输出维度的情况下,引入非线性变换,增加网络的表达能力,降低计算量。
- 训练时,先训练级别简单(层数较浅)的VGGNet的A级网络,然后使用A网络的权重来初始化后面的复杂模型,加快训练的收敛速度。
- 采用了Multi-Scale的方法来训练和预测。可以增加训练的数据量,防止模型过拟合,提升预测准确率。
VGG的缺点
VGG16具有如此之大的参数数目,可以预期它具有很高的拟合能力;但同时缺点也很明显:
- 即训练时间过长,调参难度大。
- 需要的存储容量大,不利于部署。例如存储VGG16权重值文件的大小为500多MB,不利于安装到嵌入式系统中。
VGG相关的问题
之前的网络都用7x7,11x11等比较大的卷积核,现在全用3x3不会有什么影响吗?
几个小滤波器卷积层的组合比一个大滤波器卷积层好:
假设你一层一层地重叠了3个3x3的卷积层(层与层之间有非线性激活函数)。在这个排列下,第一个卷积层中的每个神经元都对输入数据体有一个3x3的视野。第二个卷积层上的神经元对第一个卷积层有一个3x3的视野,也就是对输入数据体有5x5的视野。同样,在第三个卷积层上的神经元对第二个卷积层有3x3的视野,也就是对输入数据体有7x7的视野。假设不采用这3个3x3的卷积层,二是使用一个单独的有7x7的感受野的卷积层,那么所有神经元的感受野也是7x7。
但是,多个卷积层与非线性的激活层交替的结构,比单一卷积层的结构更能提取出深层的更好的特征。此外,假设所有的数据有C个通道,那么单独的7x7卷积层将会包含 7*7*C=49C个参数,而3个3x3的卷积层的组合仅有个3*(3*3*C)=27C个参数。直观说来,最好选择带有小滤波器的卷积层组合,而不是用一个带有大的滤波器的卷积层。前者可以表达出输入数据中更多个强力特征,使用的参数也更少。
唯一的不足是,在进行反向传播时,中间的卷积层可能会导致占用更多的内存。
虽然网络层数加深,但VGG在训练的过程中比AlexNet收敛的要快一些,为什么?
主要因为:
- 使用小卷积核和更深的网络进行的正则化;
- 在特定的层使用了预训练得到的数据进行参数的初始化。对于较浅的网络,如网络A,可以直接使用随机数进行随机初始化,而对于比较深的网络,则使用前面已经训练好的较浅的网络中的参数值对其前几层的卷积层和最后的全连接层进行初始化。
代码实现
模型需求分析
对模型进行抽象和分析,以便写出更优美的代码~
由VGG多个变种的结构图可知,主要包括5个卷积块和一个分类块,可以考虑用一个函数对5个卷积块进行包装,传入的参数为channel大小和层数,利用nn.Sequential函数把块中的各个层串联起来。
代码
import torch.nn as nn |
构建模型
网络的深入通过一个数组控制,数组的元素没每个卷积层组内卷积层的数量。
def VGG_11(): |
打印模型
def test(): |
#打印结果 |
