Transformer相关——(6)Normalization方式
Transformer相关——(6)Normalization方式
引言
经过了残差模块后,Transformer还对残差模块输出进行了Normalization,本文对Normalization方式进行了总结,并回答为什么Transformer中选择使用Layer Normalization而不是Batch Normalization的问题。
为什么要做Normalization?
Normalization通过将一部分不重要的信息损失掉,以此来降低拟合难度以及过拟合的风险,从而加速模型收敛。其目的是让分布稳定下来(降低各个维度数据的方差)。
不同的特征具有不同数量级的数据,它们对线性组合后的结果的影响所占比重就很不相同,数量级大的特征显然影响更大。做Normalization可以协调在特征空间上的分布,更好地进行梯度下降;
在神经网络中,特征经过线性组合后,还要经过激活函数,如果某个特征数量级过大,在经过激活函数时,就会提前进入它的饱和区间(比如sigmoid激活函数),即不管如何增大这个数值,它的激活函数值都在 1 附近,不会有太大变化,这样激活函 ...
Transformer相关——(5)残差模块
Transformer相关——(5)残差模块
引言
上一篇我们已经说完了Transformer中encoder的核心,这一篇我们来说一下mulit -head self-attention输出后为什么接了一个残差模块。我们先来看下残差模块解决了什么问题,然后再分析残差结构为什么可以解决这些问题。
残差模块解决了什么问题?
一定程度上可以缓解梯度弥散问题:
现代神经网络一般是通过基于梯度的BP算法来优化,对前馈神经网络而言,一般需要前向传播输入信号,然后反向传播误差并使用梯度方法更新参数。
根据链式法则,当导数<1时,会导致反向传播中梯度逐渐消失,底层的参数不能有效更新,这也就是梯度弥散(或梯度消失);当 导数>1 时,则会使得梯度以指数级速度增大,造成系统不稳定,也就是梯度爆炸问题。此问题可以被标准初始化和中间层正规化方法有效控制,这些方法使得深度神经网络可以收敛。
一定程度上解决网络退化问题:
在神经网络可以收敛的前提下,随着网络深度增加,网络的表现先是逐渐增加至饱和,然后迅速下降。
网络退化问题不是过拟合导致的,即便在模型训练过程中 ...
Transformer相关——(4)Poisition encoding
Transformer相关——(4)Poisition encoding
引言
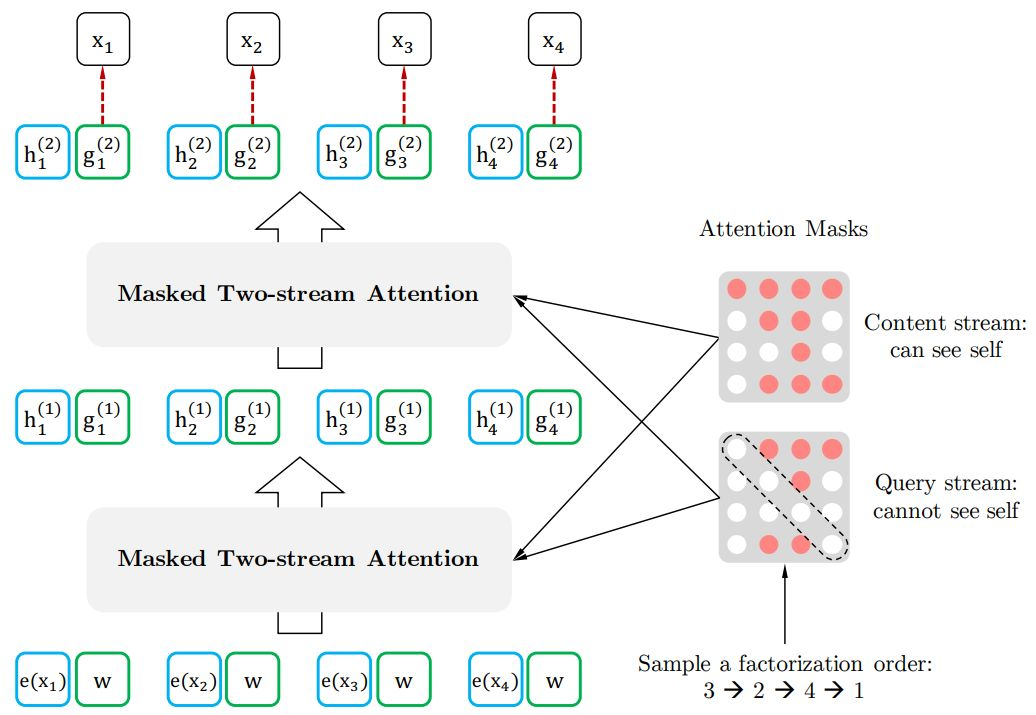
上一篇总结完了attention机制,其中提到Transformer中的self-attention机制可以并行化但是缺乏位置信息,各个位置完全没有任何差别,这导致了什么问题呢?比如在一个句子中,某一个词汇它是放在句首的,那它是动词的可能性可能就比较低,这种位置信息可能在NLP的命名实体识别任务中很有用。
positional encoding位置编码就可以补充上述这类位置信息。
Poisition encoding
Poisition encoding应用在哪
Poisition encoding位置编码机制为每一个位置设定一个 vector,叫做 positional vector(\(e^i\)),不同的位置都有一个它专属的位置编码,然后把\(e^i\)加到\(a^i\)上,再做self-attention操作。
怎么设计Poisition encoding
Poisition encoding是人工设计的,最好能满足以下条件:保证值域固定,且不同长度文本,相差相 ...
Transformer相关——(3)Attention机制
Transformer相关——(3)Attention机制
引言
这篇我们来总结一下attention机制。
Attention的直观理解
与人类对外界事物的观察机制很类似,在某种情景下(根据不同的任务可能关注点不同)我们注意力会集中在这张图片的一个区域内,而其他的信息受关注度会相应降低。Attention机制让神经网络更聚焦于对那些对最终任务有帮助的部分。比如下图的各个子图中,模型对句子下划线部分更加关注(越亮)。
再举NLP中的一个例子来说,我们在做阅读理解时,文中隐藏需要回答问题的答案的关键词/句更加关注,神经网络通过attention机制试图寻找问题答案的时候关注哪些方面。
Attention机制/模块
Attention的实质是加权求和。通过一个额外的神经网络层,用于选择输入的某些部分或者给输入的不同部分分配不同的权重。这个权是通过计算向量之间的相关性进行度量的。
我个人理解来看,可以直观理解attention是一种不规则的感受野,对整张图像或者整篇文档都有感知,且在局部重点感知。
Attention机制分类(了解)
按可微性分
...
Transformer相关——(2)Seq2Seq模型
Transformer相关——(2)Seq2Seq模型
引言
上一节介绍了Encoder-Decoder框架,基于该框架设计的模型输入可以是一个向量(如最原始CNN的输入是图像经过flatten后的向量,下图红框部分,往往将数据处理成固定大小的向量作为输入):
当面对更复杂的问题时,比如说面对一些具有时序特征的向量序列、具有顺序特征的序列,其表示成序列后,长度事先并不知道,那么为了适应这种输入是多个向量,而且这个输入向量的数目是会改变的的场景,需要设计新的模型。
当输入是多个向量时,Decoder的输出可以有以下三种形式:
输出个数与输入向量个数相同,即每一个向量都有对应的一个label或value(如命名实体识别NER、词性标注POS tagging等任务),也叫Sequence Labeling;
只需要输出一个Label或value(比如文本分类、情感分析);
输出个数与输入向量个数不一定相同,机器要自己决定应该要输出多少个Label或value(比如文本翻译、语音识别),也叫做sequence to sequen ...
Transformer相关——(1)Encoder-Decoder框架
Transformer相关——(1)Encoder-Decoder框架
引言
Transformer采用经典的encoder-decoder框架,是一个基于self-attention来计算输入和输出表示的模型,现已被应用于计算机视觉、自然语言处理等领域,都有非常好的效果。
从这篇开始的“Transformer相关”博文,将尽可能覆盖Transformer触及的相关知识,一起手撕Transformer~
Encoder-Decoder框架
Encoder-Decoder框架可以看作是一种深度学习领域的研究模式,即:将现实问题转化为一类可优化或者可求解的数学问题,利用相应的算法来实现这一数学问题的求解,然后再应用到现实问题中,从而解决了现实问题。
Encoder-Decoder框架分为Encoder(编码器)和Decoder(解码器)两个部分,分别实现现实问题->数学问题的转化和求解数学问题->现实问题解决方案的转化。
对于文本领域的Encoder-Decoder框架的实际模型案例比如,输入一个句子序列\(X_1,X_2,X_3...\)经过enco ...

西瓜书阅读笔记——第6章-支持向量机(核函数6.3、6.6)
西瓜书阅读笔记——第6章-支持向量机(核函数6.3、6.6)
引言
在现实任务中,原始样本空间内许并不存在一个能正确划分两类样本的超平面。
将样本从原始空间映射到一个更高维的特征空间,使得样本在这个特征空间内线性可分。
令\(\phi(\mathbf x)\)表示将\(\mathbf x\)映射后的特征向量。那么,在特征空间中划分超平面所对应的模型可表示为: \[
f(\mathbf x)=\mathbf w^T\phi(\mathbf x)+b
\] 则其策略为: \[
\begin{align}
\min_{\mathbf w,b}& \frac{1}{2}||\mathbf w||^2
\\s.t. 1-y_i(\mathbf w^T&\phi(\mathbf x_i)+b)≤0, i=1,2,...,m
\end{align}
\] 其对偶问题为: \[
\begin{align}
\max_{\mathbf α} \sum_{i=1}^mα_i-\frac{1}{2}\sum_{i=1}^m&\sum_{j=1}^m ...
西瓜书阅读笔记——第6章-支持向量机(软间隔6.4、6.5)
西瓜书阅读笔记——第6章-支持向量机(软间隔6.4、6.5)
强烈推荐配合西瓜书阅读使用的南瓜书和南瓜书作者录制的学习视频【吃瓜教程】《机器学习公式详解》(南瓜书)与西瓜书公式推导直播合集。
上一篇博客讨论线性可分的数据集,但事实上在现实任务中,线性不可分的情形才是最常见的,因此需要允许支持向量机犯错,因此引入软间隔的概念。
软间隔支持向量机
软间隔soft margin
硬间隔hard margin:所有样本均满足约束,即所有样本都必须划分正确。
软间隔soft margin:允许部分样本不满足约束。
据此可设计优化目标为:
其他常见的替代损失(surrogate loss)函数包括:
进一步,引入"松弛变量"(slack variables)\(\xi_i≥0\),表示每个样本不满足约束\(y_i(\mathbf w^T\mathbf x_i+b)≥1\)的程度。
同样可证明该问题为凸优化问题,(见西瓜书阅读笔记——第6章-支持向量机(硬间隔6.1、6.2) | 冬于的博客 (ifwind.github.io));
...
西瓜书阅读笔记——第6章-支持向量机(硬间隔6.1、6.2)
西瓜书阅读笔记——第6章-支持向量机(硬间隔6.1、6.2)
强烈推荐配合西瓜书阅读使用的南瓜书和南瓜书作者录制的学习视频【吃瓜教程】《机器学习公式详解》(南瓜书)与西瓜书公式推导直播合集。
硬间隔支持向量机
模型
几何角度
找距离正负样本都最远的超平面,与感知机的区别,该模型的超平面解是唯一的,泛化性能更好,不偏不倚。
数学角度
点到超平面的距离公式:
支持向量support vector
距离超平面最近的这几个训练样本使得等式等号成立称为支持向量。
间隔margin
两个异类支持向量到超平面的距离之和。
几何间隔
模型
策略
由上面可推断,一个好的超平面,数据集\(X\)样本点中,距离该超平面几何间隔最小的样本点的几何间隔\(γ\)越大越好。
对于一般约束优化问题,希望以下表示:
最小化目标函数
将约束条件转化为\(g_i(·)≤0\)或\(h_i(·)=0\)的形式
于是,进一步将上式转化为: \[
\begin{align}
\min_{\mathbf w,b}\space \frac{1}{2}|| ...
西瓜书阅读笔记——第5章-神经网络
西瓜书阅读笔记——第5章-神经网络
M-P神经元模型
神经元接收到来自n个其他神经元传递过来的"输入信号"{\(x_1,x_2,...,x_n\)},输入信号通过带权重{\(w_1,w_2,...,w_n\)}进行加权和,神经元接收到的总输入值减去神经元的"阈值"\(\theta\),然后通过"激活函数"(activation function)\(f(·)\)处理以产生神经元输出\(y\)。
单个M‑P神经元:感知机( 阶跃函数sgn作激活函数)、对数几率回归(sigmoid作激活函数) 多个M‑P神经元:神经网络。
感知机 Perceptron
模型
数学表示
感知机(Perceptron)由两层神经元组成。输入层接收外界输入信号后传递给输出层,输出层是M-P神经元,亦称"阈值逻辑单元"(threshold logic unit)。
感知机只能实现逻辑与、或、非运算。
激活函数为sgn (阶跃函数)的神经元: \[
\begin{align}
y = ...