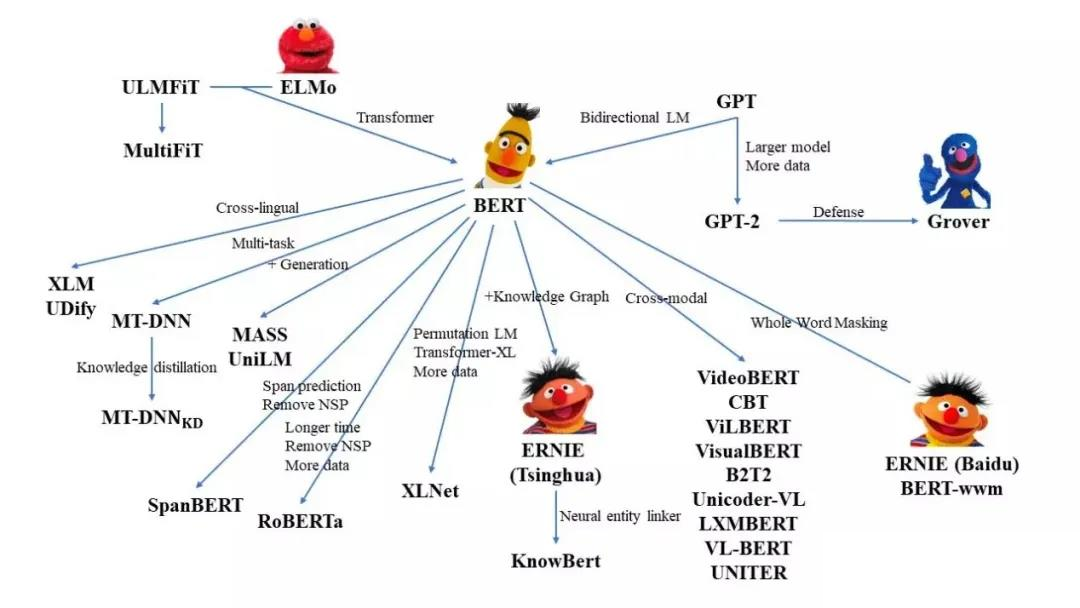
BERT相关——(2)Contextualized Word Embedding和ELMO模型
BERT相关——(2)Contextualized Word Embedding和ELMO模型
引言
文字要如何转为数字化表示呢?
文字特征表示
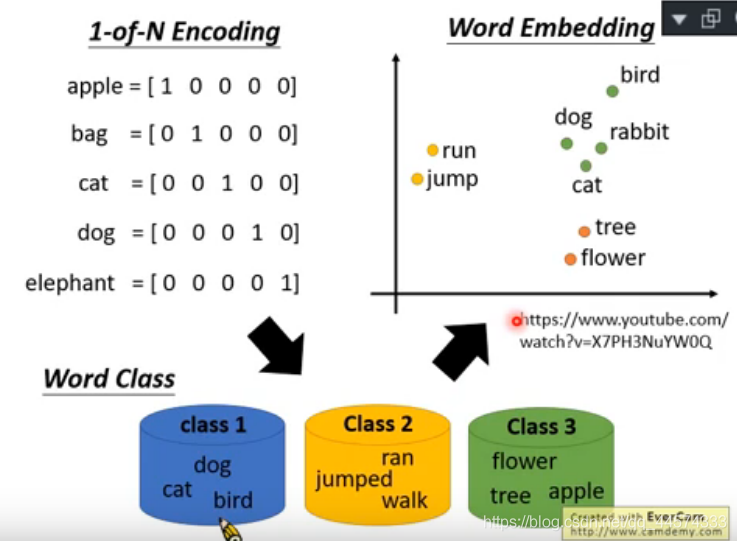
1-of-N Encoding
其实就是把字典作one-hot编码。每一个词汇都当作一个不同的符号,最常见的做法就是1-of-N Encoding,如下图所示,把词表中的每一个词用一个独热编码表示。这种编码下,每个词汇都是完全没有关系的(特征表示向量正交)。
Word Class
Word Class是将词表中每个词分类,用这个类别表示其中的所有词汇,但仍然太粗糙了,忽视了同一类中每个词的意义。
Word Embedding
Word Embedding是指把每一个词汇都用高维向量表示,这个向量的每一个维度可能就表示了这个词汇某些方面的意思。这样语义相近的词汇,其向量也更加接近,如上图所示,run和jump都是动词,它们的高维向量经过降维后显然更接近。
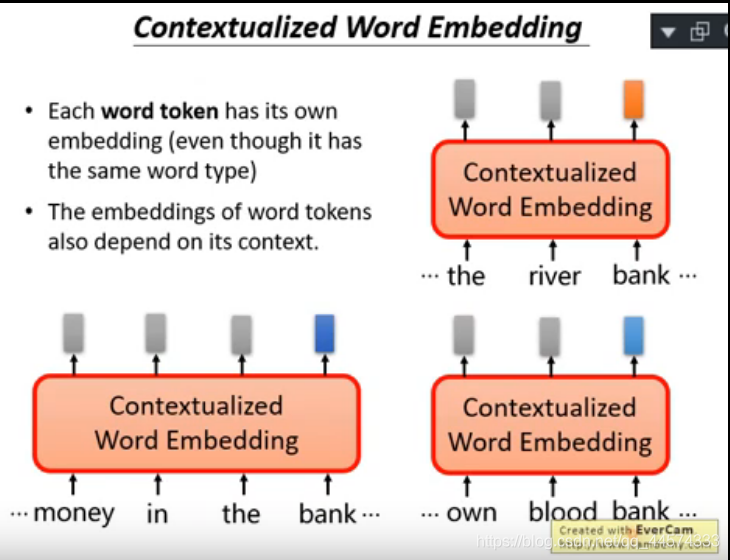
Contextualized Word Embedding
Word Embedding仍有一个问题,那就是同一个词汇,无论上下文如何变化,其表示都是固定的,无法表达词汇的多义性。比如:苹果一词在“我喜欢吃苹果”和“我喜欢用苹果”两个句子中的语义差别很大。
那该怎么表示同一个词汇在不同语境下的不同意思呢?
Contextualized Word Embedding= Word Embedding + 上下文,指的就是这种不同语境下词语的特征表示。
ELMO是经典的表示上下文词向量的模型。
ELMO模型
ELMo 没有对每个单词使用固定的词嵌入,而是在为每个词分配词嵌入之前,查看整个句子,融合上下文信息。它使用在特定任务上经过训练的双向 LSTM 来创建这些词嵌入。
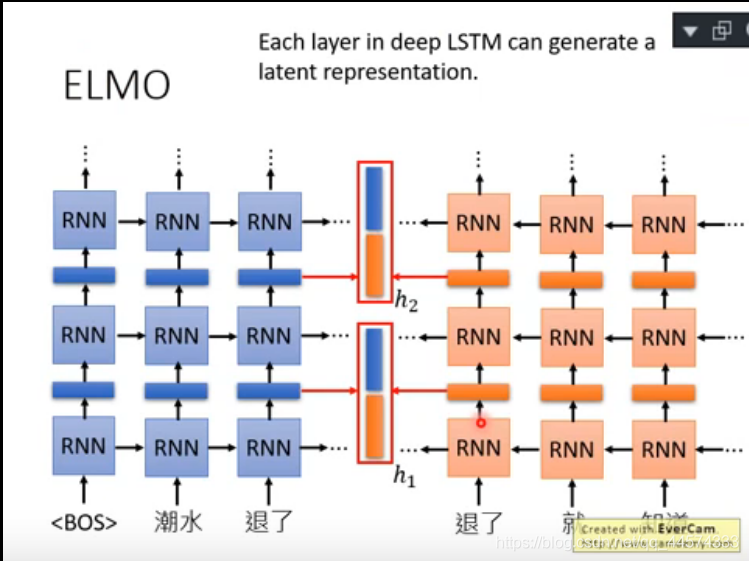
ELMO是一个双向的RNN-based language model,且是自监督训练方式,不需要标记数据,只需要大量的普通文本就可以进行训练。它的训练目标是根据已有的上文预测输出下一个token。
如下图左侧的正向RNN所示,模型根据<BOS>预测“潮水”,<BOS>+”潮水“预测“退了”,<BOS>+“潮水”+“退了”预测“谁”,以此类推。但这样每一个词的词向量仅考虑了上文,而忽略了后文的影响。因此,ELMO中 又加了下图右侧的反向RNN来同样生成词向量,此时模型需要根据 <EOS>预测“裤子”, <EOS>+“裤子”预测“没穿”,<EOS>+“裤子”+”没穿“预测“谁”,以此类推。最终预测结束后,将正向和反向的RNN隐藏层拼接作为对应输入词的词向量表示。
当然,ELMO不仅仅使用一层RNN,而是很多层RNN,所以一个词汇将会由多层RNN中每一层的正向RNN和反向RNN各得到一个词向量,ELMO不是简单将最后一层输出作为词向量,而是采用 Weighted Embedding的方式将每层的向量加权相加得到最终的词向量,如下图所示的\(\alpha_1\)和\(\alpha_2\)就是层1和层2的权重参数,这个权重参数是跟着下游任务一起训练得到的。
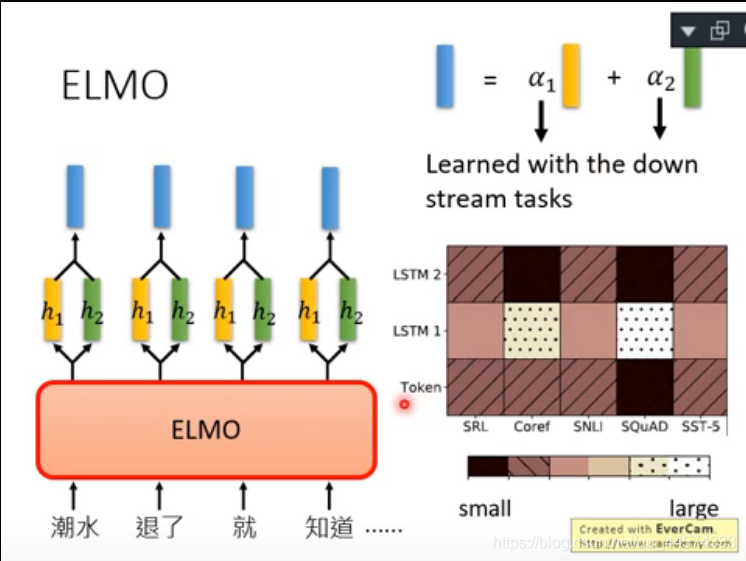
对于不同任务可视化不同层的权重值,可以看到如上图右侧所示,对不同下游任务模型不同层提取到的信息是不同的,Coref和SQuAD任务,在LSTM第一层的embedding权重更大。
ELMO存在什么问题?
显然ELMO存在所有RNN相关的问题,比如学习不到距离当前词位置很远的词特征;无法并行化训练速度慢等等。之前提到RNN已经很大程度上被self-attention替代了,下一篇就介绍利用BERT模型学习Contextualized Word Embedding。