BERT相关——(4)GPT-2模型
BERT相关——(4)GPT-2模型
引言
与BERT不同,GPT-2 是使用 Transformer 的 Decoder 模块(但实际上也不是完整的Decoder模块)构建的。且GPT-2 和传统的语言模型一样,一次输出一个token,这也与BERT不同。此外,GPT-2 能够处理 1024 个 token,这比原始的Transformer能处理的最长序列(512)要长。
因为之前“Transformer相关”系列的博客已经将 Transformer 的 Decoder 模块解剖过了,所以在基于Transformer 内部模块的模型介绍中,对这部分的内容都会比较简单地带过。有易忘记得回看一下之前的内容~
GPT-2模型
GPT-2模型结构
处理非监督文本\((y_1,y_2,...,y_m)\)的普通方法是用语言模型去最大化语言模型的极大似然。
\(L_1(X)=\sum_i\log P(y_i|y{i−k},...,y{i−1}:θ)\)
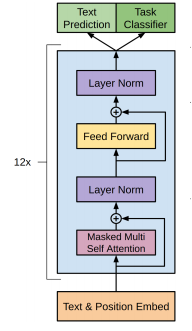
OpenAI 的 GPT-2 使用了与Transformer 中原始Decoder 模块非常类似的模块进行堆叠,但它们去掉了第二个 Self Attention 层(也就是去掉了和Encoder交互的Cross attention层)。这个多层的结构应用multi-headed self-attention在处理输入的文本加上位置信息的前馈网络,输出是词的概念分布。 \[ h_0=UW_e+W_p\\ h_l=transformer\_block(h_{l−1})\\ P(u)=softmax(h_nW^T_e) \] 结构如下图所示:
positional encoding
最后训练好的GPT-2模型两个权重矩阵:token encodings和positional encodings,也就是说positional encodings是随着网络一起训练的。positional encoding参考之前写的博客:Transformer相关——(4)Poisition encoding。
masked multi-headed self-attention
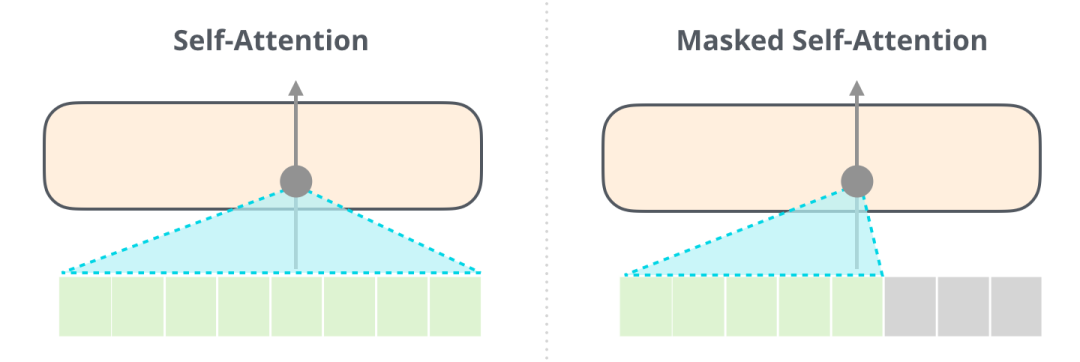
回忆一下Encoder中Self Attention(BERT 使用的)和Decoder中masked Self Attention(GPT-2 使用的)的区别:一个正常的 Self Attention 模块允许一个位置关注到它右边的部分。而 masked Self Attention 不允许模型看到下文。
GPT-2 全连接神经网络
全连接神经网络是用于处理 Self Attention 层的输出,这个输出的表示包含了合适的上下文。之前在Transformer相关——(8)Transformer模型中提到:
Position-wise Feed-Forward netword是一个全连接网络,包含两个线性变换和一个非线性函数(ReLU)。公式如下: \(FFN(x)=max(0,xW_1+b_1)W_2+b_2\)
全连接神经网络由两层组成。
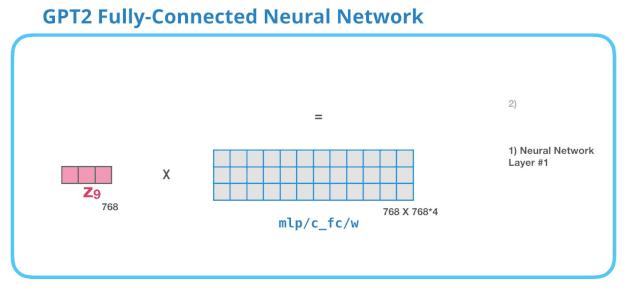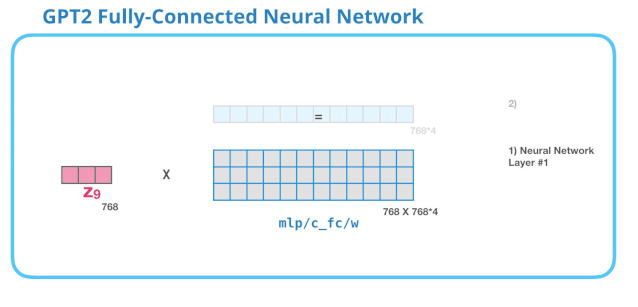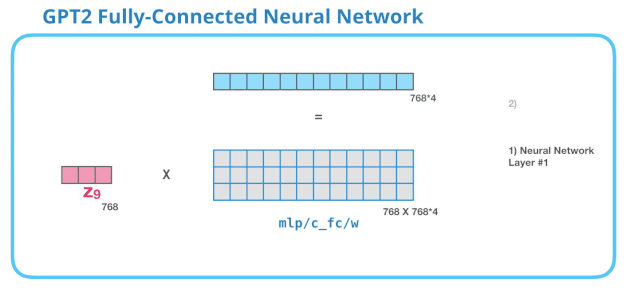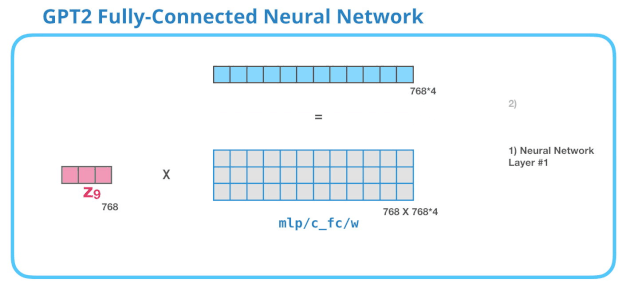
GPT-2中FFN的第一个线性变换
第一层是模型大小的 4 倍。为什么是四倍?这只是因为这是原始 Transformer 的大小(如果模型的维度是 512,那么全连接神经网络中第一个层的维度是 2048)。这似乎给了 Transformer 足够的表达能力,来处理目前的任务。
下图展示了第一层线性变换,没有展示 bias 向量。
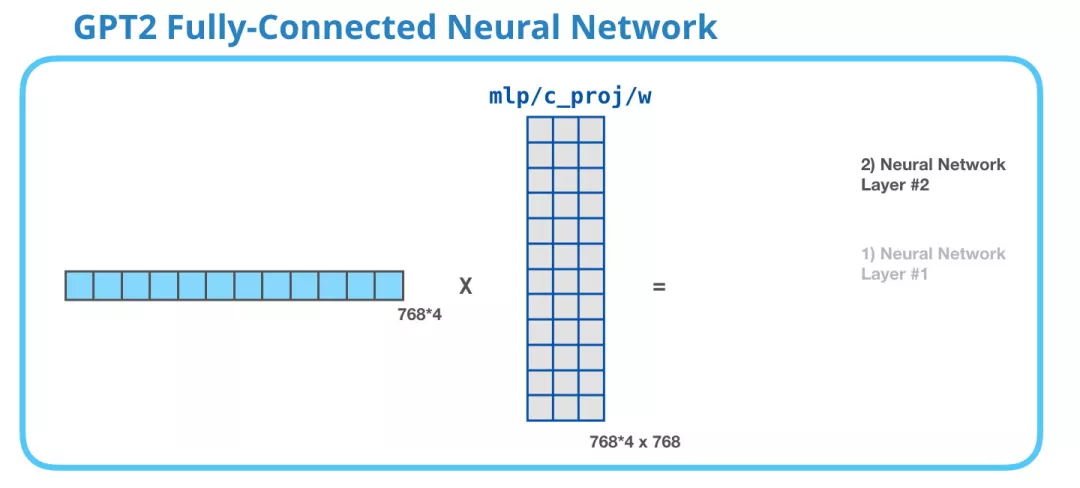
GPT-2中FFN的第二个线性变换
第 2 层把第1层得到的结果映射回模型的维度(在 GPT-2 small 中是 768)。这个相乘的结果是 Transformer 对这个 token 的输出。
GPT-2的运行机制
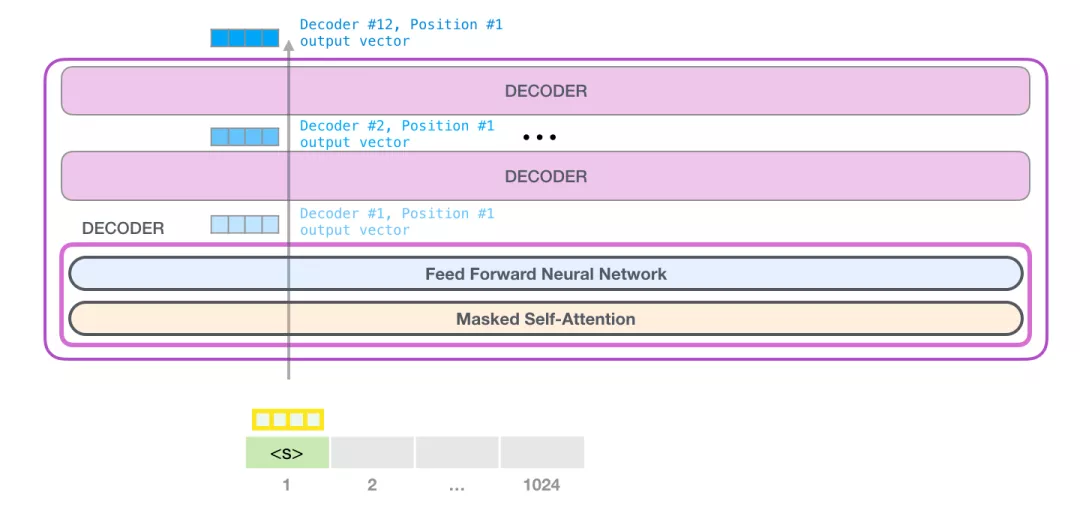
GPT-2的运行机制是一种“自回归(auto-regression)”的思想:在产生每个 token 之后,将这个 token 添加到输入的序列中,形成一个新序列。然后这个新序列成为模型在下一个时间步的输入。这种做法可以使得 RNN 非常有效。就像下面这张图:
在开始时,我们会在嵌入矩阵查找第一个 token <s> 的 embedding。在把这个 embedding 传给模型的第一个模块之前,需要融入位置编码,这个位置编码能够指示单词在序列中的顺序。位置编码矩阵包括了 1024 个位置中每个位置的位置编码向量。

然后,第一个类似Decoder的模块开始处理 token输入的embedding。首先通过 Self Attention 层,然后通过全连接层。第一个模块处理了 token后,会得到一个结果向量,这个结果向量会被发送到堆栈的下一个模块处理。每个模块的处理过程都是相同的,不过每个模块都有自己的 Self Attention 和神经网络层。
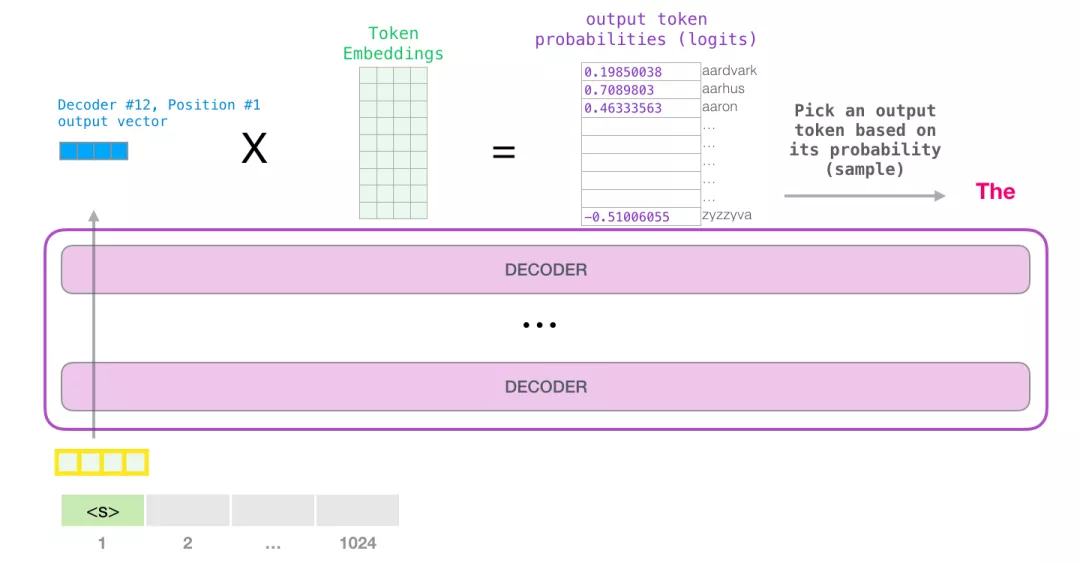
当模型顶部的模块产生输出向量时(这个向量是经过 Self Attention 层和神经网络层得到的),模型会将这个向量乘以嵌入矩阵。
可以选择最高分数的 token(top_k=1)也就是之前提到的greedy decoding 。但如果模型可以同时考虑其他词,这就像在手机输入法里面,输入了一个词以后会推荐几个下一个可能出现的词,如果一直选择第一个词可能会陷入一些奇怪的循环。
所以一个更好的策略是把分数作为单词的概率,从整个列表中选择一个单词(这样分数越高的单词,被选中的几率就越高)。一个折中的选择是把 top_k 设置为 40,让模型考虑得分最高的 40 个词,也就是Beam Search。(greedy decoding和beam search属于训练Transformer的技巧:Transformer相关——(9)训练Transformer | 冬于的博客 (ifwind.github.io))
至此,模型就完成了一次迭代,输出一个单词。模型会按照自回归的思像继续迭代,直到所有的上下文都已经生成(1024 个 token),或者直到输出了表示句子末尾的 token为止。