BERT相关——(7)将BERT应用到下游任务
BERT相关——(7)将BERT应用到下游任务
引言
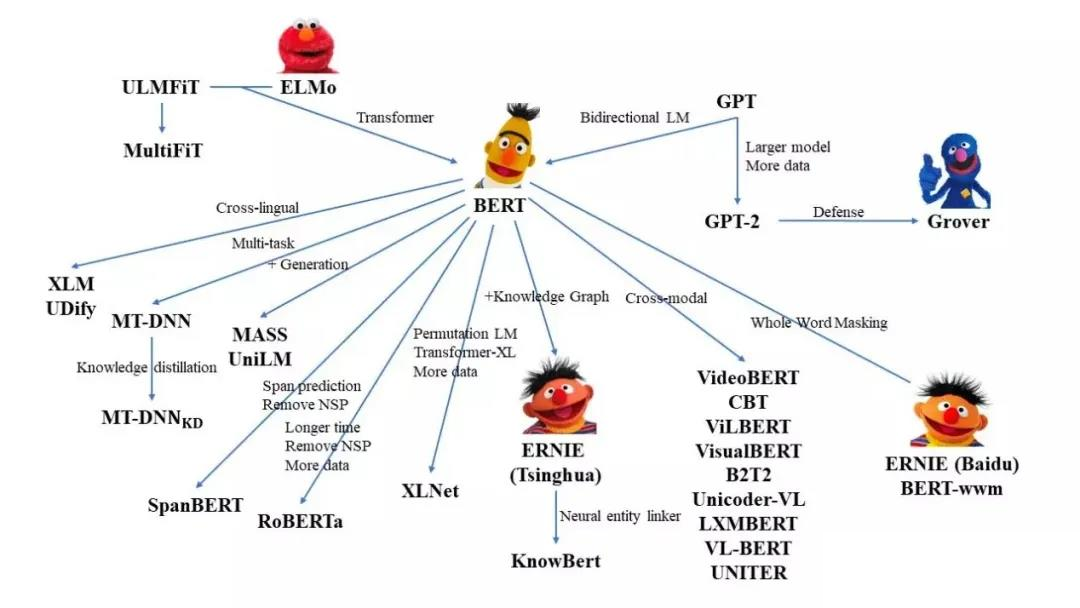
前面两篇介绍了如何从头预训练BERT并分析了BERT模型的源码。当有一个预训练模型之后,我们得到了上下文的word embedding,假设这个模型已经理解了自然语言。接着我们想在预训练模型上面再叠一些具体NLP任务的任务层,基于这个预训练模型做一些特定的NLP任务,这一步就叫微调Fine-tune。
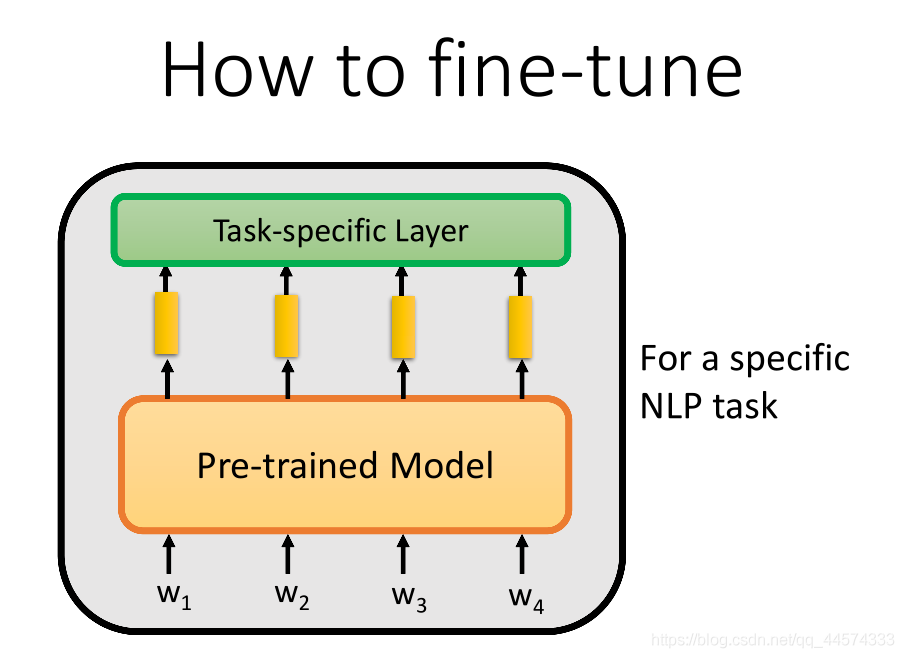
如何使用BERT进行下游任务呢?包括两种方法:
- 直接接入下游任务层;
- 利用少量标注数据进行fine-tune。
内容主要来自李宏毅老师的深度学习与人类语言处理课程(2020)。
直接接入下游任务层
Input
预训练模型的输入部分本身不需要修改;
当NLP任务的输入为一个句子时,不需要做没有什么特殊处理,比如句子分类、命名实体识别任务;
在一些问题上,需要输入多个句子时,需要每个句子之间加“[SEP]”分隔符后再输入给预训练模型。比如QA问题,要将问题和文章一起输入给模型,NLI自然语言推理问题,要将前提和假设一起输入给模型。
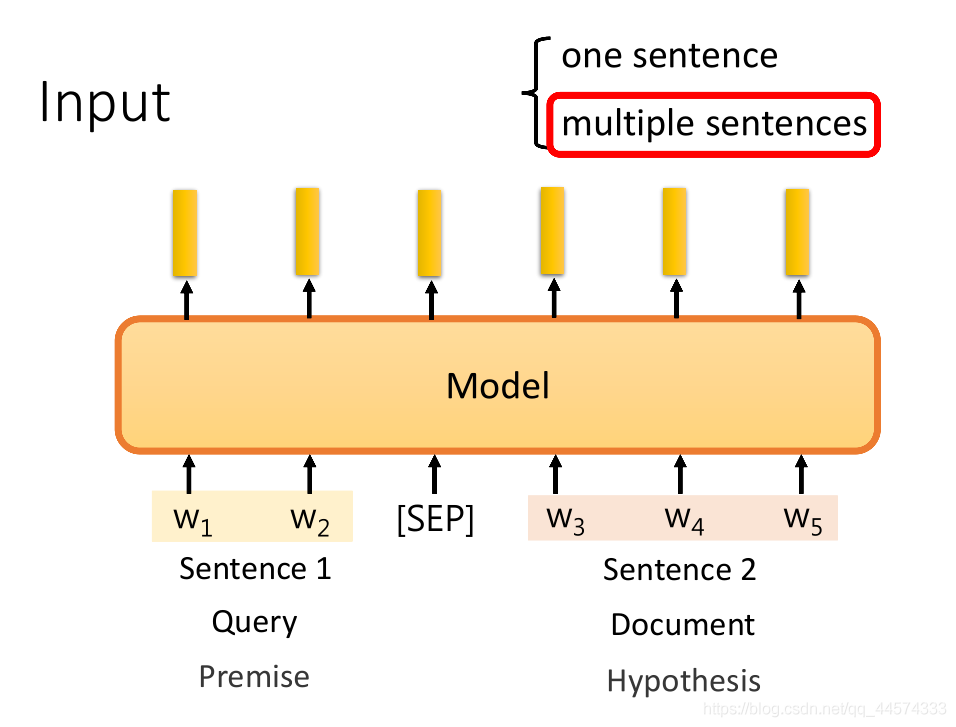
Output
输出可以分为以下四种情况:
- one class
- class for each token
- copy from input
- general sequence
one class
输入:one sentence
输出:one class
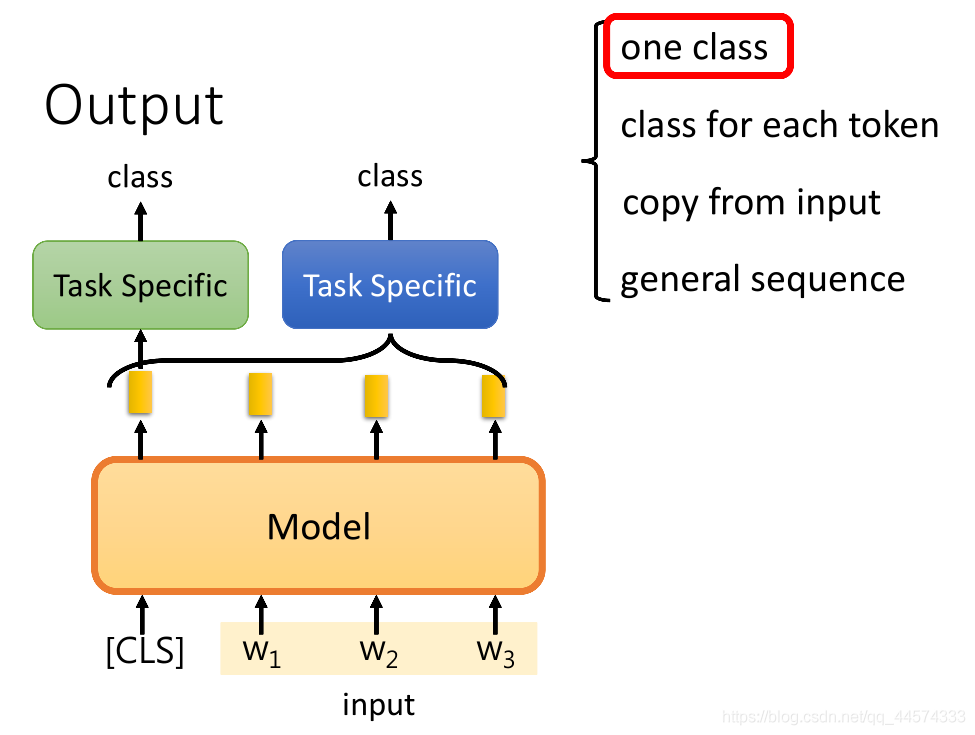
如上图,模型输入一整个句子,输出一个类别,比如句子分类。
方法1:绿色框
在原始BERT论文中解法如上图绿色框框,同样是读入所有的token sequence,并在开头加一个特殊符号“[CLS]”表示分类符号,通过"[CLS]"得到的embedding再输入给一个线性分类器里,输出类别。
方法2:蓝色框
另外一个做法是不加“[CLS]”特殊符号,把所有token的embedding sequence输入可以处理sequence的模型中,如RNN、LSTM等,再输入给一个线性分类器里输出一个类别。
class for each token
输入:one sentence
输出:class for each token
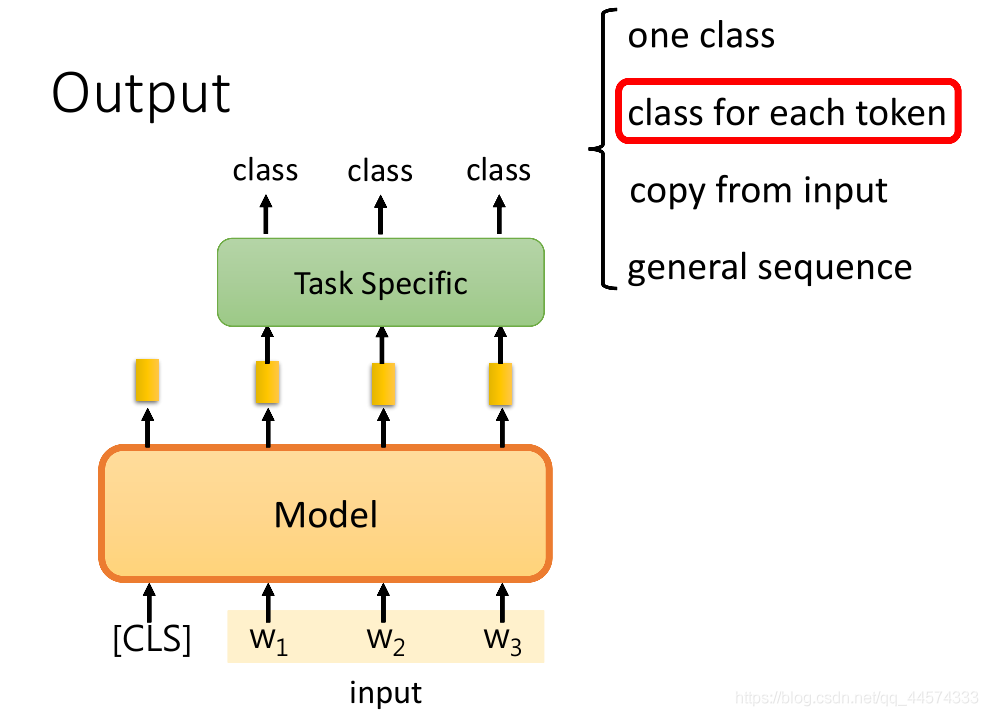
如上图,输入一整个句子,输出每个token的类别,比如命名实体识别。
需要一个可以把整个句子中,每个token经过预训练模型得到的embedding sequence当作输入,接下来对每一个embedding进行输出类别的模型,比如LSTM。
copy from input
输入:document
输出:two number
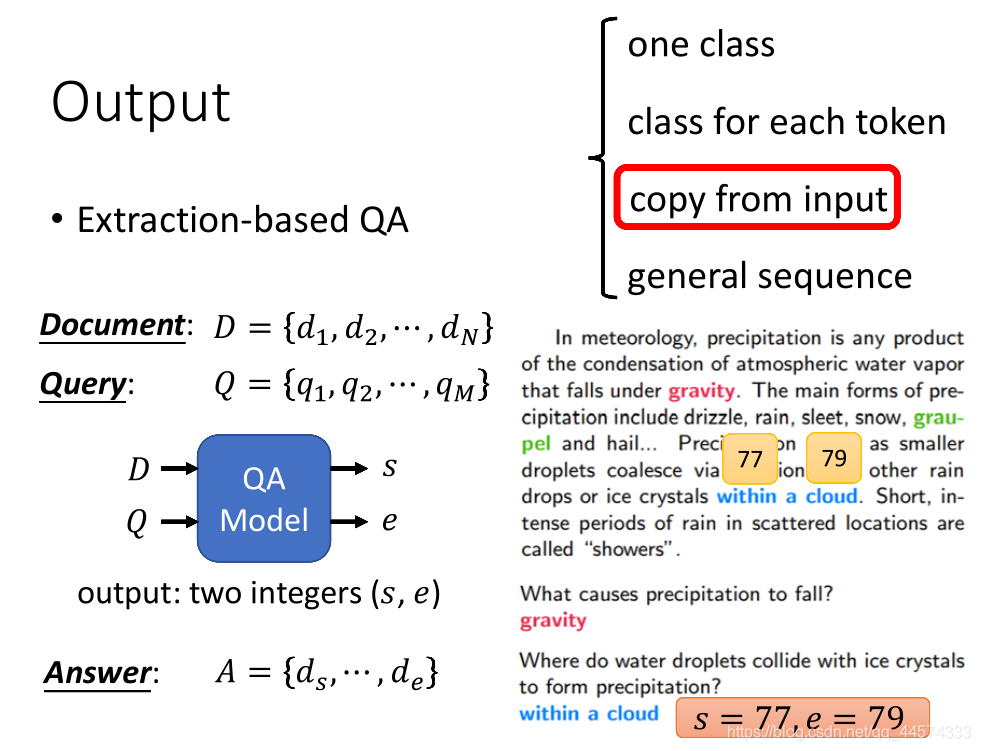
如上图,第三个任务是解类似QA问题,而且是Extraction-based Question Answering,如SQuAD。也就是说给模型读一篇文章,并提出一个问题,希望模型能正确的得到答案,且答案是原文中的一部分。
而对于模型而言,它只需要输出两个数字\(s\)和\(e\)表示起始索引和终止索引,其索引内的token sequence就是正确答案。
给一个以BERT为预训练模型进行该任务的案例:
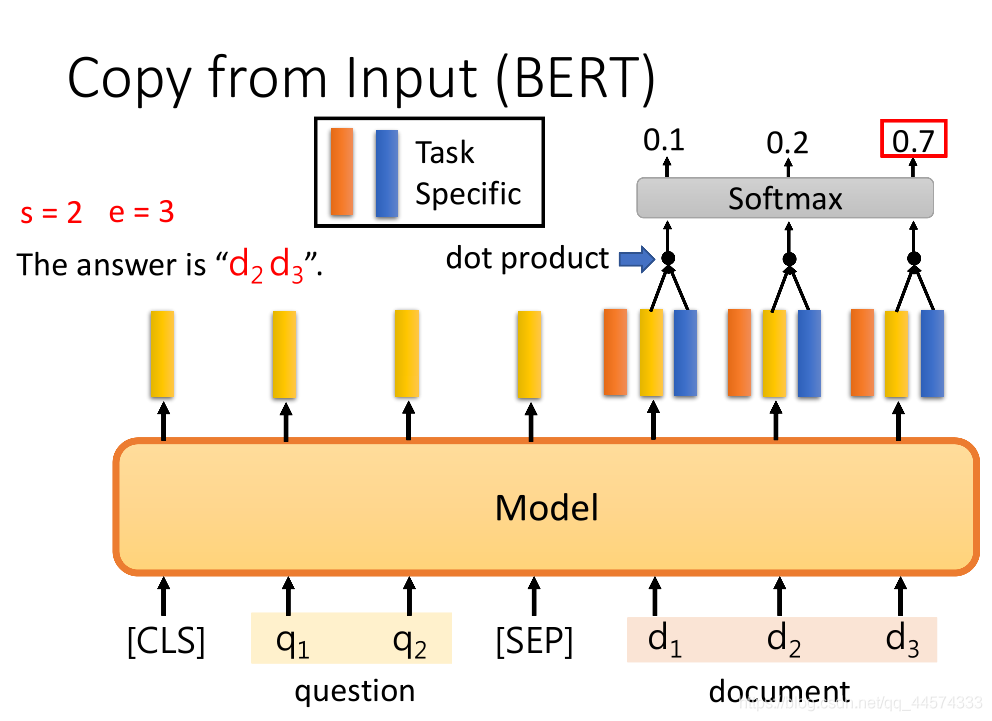
解法:将问题和文章中间加"[SEP]",开头加"[CLS]"输入给BERT,得到每一个对应位置的embedding。
另外,再从头训练 橙蓝 两个向量,其维度和 黄色embedding相同;
将橙色的向量与文章的embedding做dot-product点积运算得到每一个文章内的词汇的scalar,再将其softmax后得到对应分数,找出其中分数最高的,如上图的\(d_2\),此时\(s\)就等于2。同理,蓝色的向量与橙色的向量运算过程一样,得到\(e\)等于3。至此,答案就是\(d_s\) 至 \(d_e\)。
注意:在训练的时候,橙蓝向量从头训练,BERT微调。
此时,会有这样的问题,假设\(s\)和\(e\)矛盾了,比如\(s=3,e=2\),此时模型就是输出此题无解,在SQuAD2.0中是有无解的问题的。
general sequence
输入:sentence
输出:sentence
有两种方案让预训练模型处理seq2seq问题。
方法1
最简单的做法就是把预训练模型当作seq2seq中的Encoder,具体任务模型就是Decoder。
缺点:这个具体任务模型没有被事先预训练到。一般来说具体任务中有标注的数据很少,我们希望具体任务的模型越小越好,也就是这个具体任务模型大多数参数都是经过预训练的,但上述这种Encoder-Decoder方法显然不能预训练具体任务模型的。
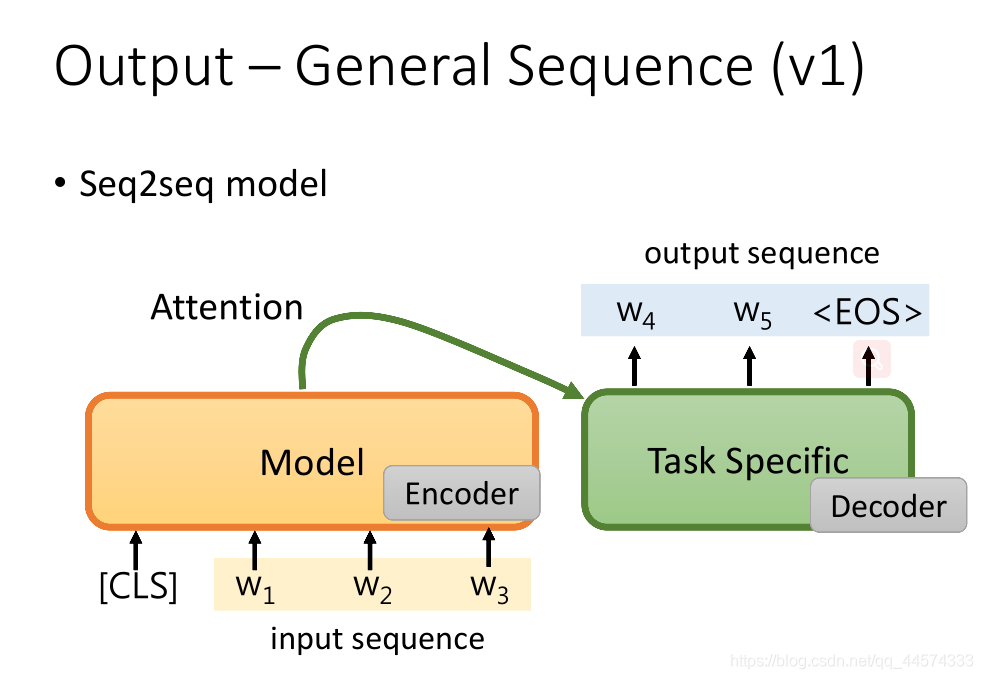
方法2
另外一种方法或许更合适。
\(w_1,w_2\) 是输入的sequence,接下来,输入一个特别的符号"[SEP]",它会输出一个embedding,将这个embedding再丢到具体训练任务模型中,然后输出产生想要输出的sequence的第一个token。接下来,再把这个token丢到预训练模型中,再产生embedding,把这个embedding同样输入到具体训练任务模型中生成第二个token,依次生成,直至具体训练任务输出"[EOS]"。
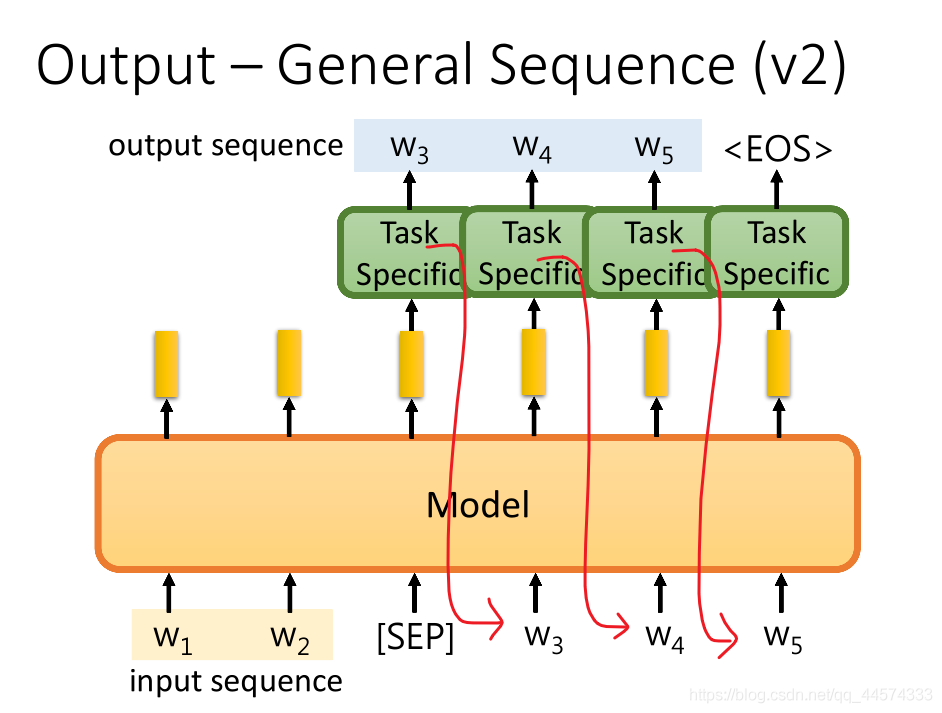
以上讲的都是怎么在预训练模型上加上什么东西,让它能够解决各式各样的具体问题。 接下来,假如我们有一些具体训练任务的有标注数据,我们该怎么微调预训练模型呢?
利用少量标注数据进行fine-tune
Methods
根据具体训练任务的有标注数据进行微调预训练模型有两种方法。
方法1
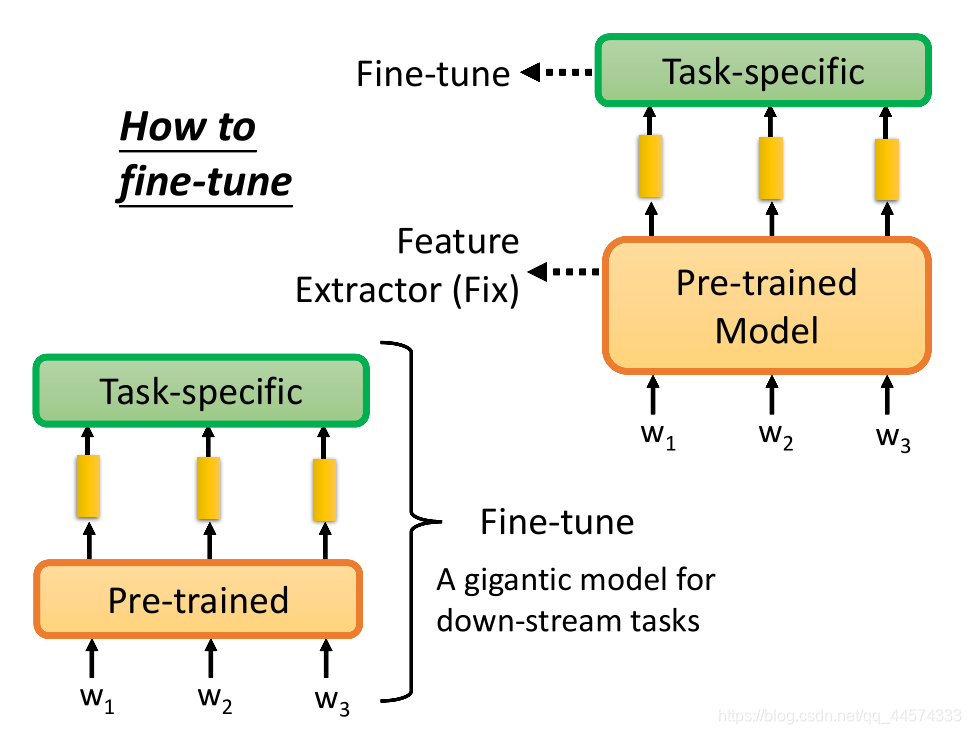
预训练模型训练完后权重固定不变,变成一个Feature Extractor特征提取器,对输入的token sequence,输出一堆的embedding表示,再将这些embedding丢到具体任务模型中,只微调具体任务模型的参数。
方法2
把预训练模型与具体任务模型接在一起,微调模型时既会微调预训练模型,也会微调具体训练任务模型。
如果直接训练这种组合起来的巨大模型,往往会过拟合,但是预训练模型的大部分已经预训练过了,只有很小部分的参数是由具体训练任务改变。在文献上,第二种方法往往优于第一种方法。
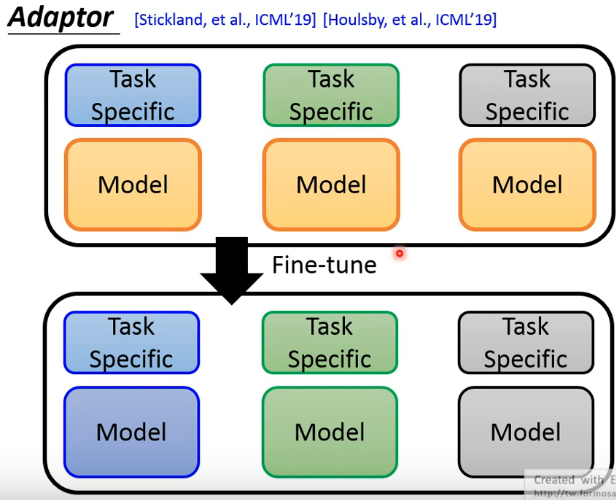
Adaptor
假设有三个具体的NLP任务,仅使用同一个预训练模型+具体任务模型的方式,如果采取的是第二种方法,Fine-tune整个巨大的模型,经过每一个具体任务数据Fine-tune整个模型后,同一个预训练模型因不同训练数据的微调会得到三种有区别的预训练模型。如下图中三个Model,每一个任务都需要存一个新的这样的预训练模型,而预训练模型往往都是非常的巨大,这样是非常不切实际的。
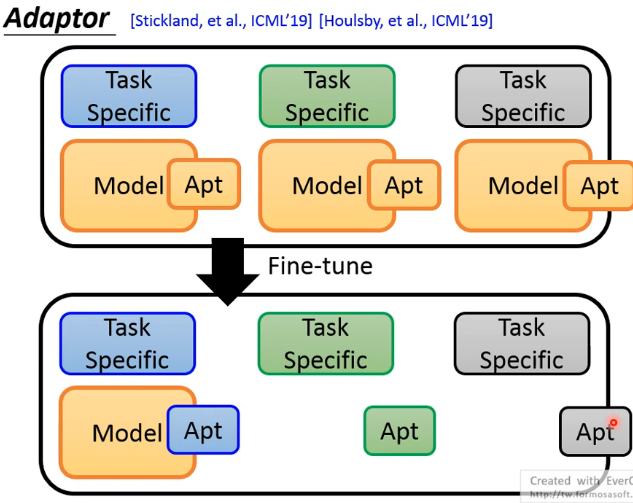
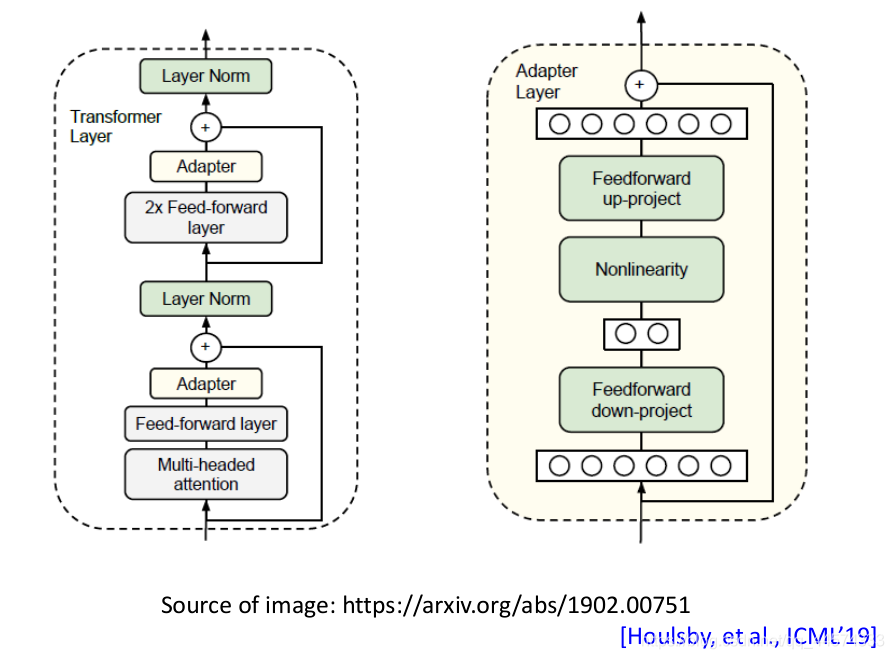
于是就有了Adaptor——对于不同的训练任务只调预训练模型的一部分。
在预训练模型中加入一些layers,这些layers就叫Adaptor,它只是模型的一小部分参数。
在根据不同训练任务微调模型时,只需调Adaptor的部分。因此,对于不同任务,我们只需要存不同的Adaptor参数和共同的一个预训练模型参数,这样的参数量就要比每一个任务都存一个预训练模型的参数量远远小得多。如下图所示:
Adaptor方法有很多,Adaptor结构示例如下图。怎样才能得到最好的Adaptor结构设计也是一个值得研究的问题。
(小细节,下图文献中是Adapter,而不是Adaptor)
Weighted Features
前面的预训练+微调的结构都是:训练模型输入token sequence,经过很多个layer层(12、24)后,得到最后一层每个token的embedding,再把这个embedding丢到具体任务里去。
但和ELMO中相似,预训练模型中每一层学到的东西是不一样的,可以把不同层的输出进行加权求和得到embedding,而其中的权重参数都是跟着具体任务训练得到的。