李宏毅深度学习2021春p53-54:Auto-Encoder
李宏毅深度学习2021春p53-54:Auto-Encoder
回顾自监督学习框架
Self-Supervised Learning/Pre-Training:有大量无标注的训练数据,不用额外标注去训练模型。把 Self-Supervised Learning 的 Model,做一点点调整,就可以用在下游的任务里面。
很流行的Bert模型就是Self-Supervised Learning的模型,更古老的不需要用标注资料的任务,就是Auto-Encoder。

Auto-Encoder
Auto-Encoder训练的目标是希望Encoder 的输入跟 Decoder 的输出越接近越好,这个过程也可以叫做重建reconstruction。
如下图所示,Encoder(可能是多层CNN)将图片编码成一个vector,Decoder根据这个vector还原原始图片。

与CycleGAN类似,但是自编码器不需要任何标注资料,只需要收集大量图片就可以进行训练。
如何将训练好的Auto-Encoder用到下游任务?
只需要用到Auto-Encoder的Encoder部分,将图片进行编码,也就是通过 Encoder 的压缩以后,变成了一个低维度的向量,再拿这个低维度的向量开展下游任务。

这种把高维度的东西转成低维度的东西,也叫做 Dimension Reduction。
非深度学习的降维方法如PCA、t-SNE等:

为什么要用Auto-Encoder
Encoder 做的事情就是化繁为简,本来比较复杂的东西,它只是表面上比较复杂,事实上它的变化其实是有限的,只要找出它有限的变化,就可以把本来复杂的东西用比较简单的方法来表示。
这样在下游的任务里面,可能就只需要比较少的训练资料就可以让机器学到我们本来要它学的事情,这就是Auto-Encoder为什么有用。
去噪Auto-Encoder(De-noising Auto-encoder)
De-Noising 的 Auto-Encoder 是把原来要输进去给 Encoder 的图片,加上一些噪声,然后一样通过 Encoder,一样再通过 Decoder,试图还原没有加噪声的、原来的图片。
现在 Encoder 跟 Decoder除了还原原来的图片这个任务以外,它还多了一个任务,它必须要自己学会把噪声去掉。

与BERT模型的关系
BERT 也可以看作就是一,De-Noising 的 Auto-Encoder。
输入的句子会加 Masking(其实就是 Noise),BERT 的模型就是 Encoder,它的输出就是 Embedding,接下来有一个 Linear 就是 Decoder,Decoder 要做的事情,就是还原原来的句子,把被盖住的地方还原回来。

当然这个Decoder 不一定要是 Linear,比如说也可以将BERT某一层的输出作为embedding,该层之前都是Encoder,之后的层都是Decoder。
对抗性自编码(Adversarial AutoEncode)
将对抗的思想融入到Autoencoders中来。如下图所示,上半部分就是AE,把一个真实分布映射成隐层的z,AAE就是在z这里加上对抗思想,通过微调z来生成更加真实的样本,来优化这个z。


红框中就是一个AE,对抗思想的引入在于黄框中的内容,AE的encoder部分,作为GAN中的generator,生成样本,也就是编码层中的编码,与黄框左边部分的真实样本,一个符合p(z)分布的样本混在一起让discriminator进行辨别,从而使discriminator与作为generator的encoder部分不断优化,并且在对抗的同时,AE也在最小化reconstruction error,最终可以生成更好的样本。
Feature Disentangle特征解耦
embedding通过 Decoder 重构回原来的文章,embedding中可能包含语法信息、语义信息等等,但是这些信息是全部纠缠在一个向量中,我们并不知道一个向量的哪些维代表了哪些信息。
举例来说,如果今天把一段声音讯号丢进 Encoder,会输出一个embedding,但这个embedding哪些维度代表了这句话的内容,哪些维度代表说话的人,这是不知道的。
Feature Disentangle做的事情就是,在 Train 一个 Auto-Encoder 的时候同时知道这个 Representation,或又叫做 Embedding,或又叫做 Code的哪些维度代表了哪些信息。
举例来说embedding是 100 维的向量,Feature Disentangle就可以让我们知道,比如前 50 维代表了这句话的内容,后 50 维代表了这句话说话人的特征。

实际应用比如说:语音转换Voice Conversion。
过去在做 Voice Conversion 的时候,需要成对的声音数据,也就是假设你要把 A 的声音转成 B 的声音,要有A和B念相同句子的音频数据。
而有了 Feature Disentangle 的技术以后,也许就给分别给机器输入 A 的声音、B 的声音,A 跟 B 不需要念同样的句子,甚至不需要讲同样的语言,机器也有可能学会把 A 的声音转成 B 的声音。
如何实现呢?
假设收集到一大堆人类的声音讯号,然后拿这堆声音讯号去 Train 一个 Auto-Encoder,同时又做了 Feature Disentangle 的技术,所以知道在 Encoder 的输出中,哪些维度代表了语音的内容,哪些维度代表了语者的特征。
接下来可以把两句话,声音跟内容的部分互换,举例来说输入一个人的声音片段到 Encoder 以后,输出的embedding,并且可以某些维度代表说 的内容,某些维度代表说话人的声音,这里假设输出了100维度的embedding,前 50 维代表内容,后 50 维代表说话人的特征,接下来就把其中一个人代表说话内容的维度取出来(的前50维),和另外一个人的说话声音维度的特征取出来(后50维),拼接后给传给decoder,decoder的输出就是后者的声音说前者说的内容。

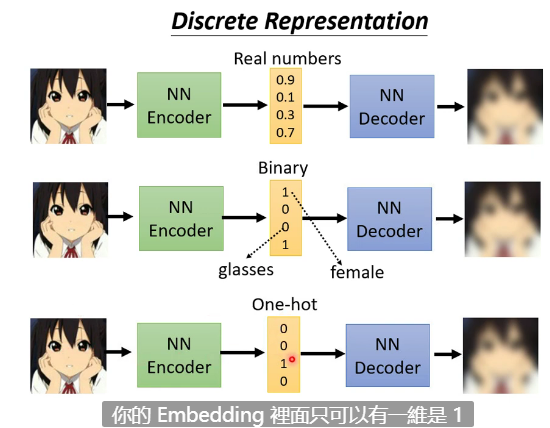
Discrete Latent Representation
到目前为止都假设这个 Embedding就是一个向量、一串数字,是 Real Numbers,但其实也可以是其他的内容,比如Binary (0/1)、one-hot、甚至一段文本。
- Binary 的每一个维度就代表了某种特征有或者是没有。比如,输入的这张图片,如果是女生,可能第一维就是 1,男生第一维就是 0;如果有戴眼镜,就是第三维 1,没有戴眼镜 就是第三维是 0。也许把 Embedding 变成 Binary,可以更好地解释 Encoder 的输出。
- one-hot只有一维是 1,其他都是 0。也就是每一个东西输入到Encoder中, Embedding里只可以有一维是 1,其他都是 0 ,也许可以做到 unSupervised 的分类。举例来说,假设有 0 到 9 的图片,把 0 到 9 的图片统统收集起来,Train 一个 Auto-Encoder,然后强迫中间的 Latent Representation一定要是 One-Hot Vector,那这个 Code 正好设为 10 维,也许每一种 One-Hot 的 Code正好就对应到一个数字。所以如果用 One-Hot 的 Vector来当做 Embedding ,也许就可以做到完全没有Llabel Data 的情况下,让机器自动学会分类。
Discrete 的 Representation 中最知名的就是 VQVAE。
VQVAE Vector Quantized Variational Auto-Encoder
输入一张图片,Encoder 输出一个向量,它是 Continuous 的,接下来有一个 Codebook(一排向量),这排向量也是 Learn 出来的,把 Encoder 的输出,跟这排向量算个相似度(其实跟 Self-attention 有点像),上面这个 Vector 就是 Query,下面这些 Vector 就是 Key。接下来就看这些 Vector 里面,谁的相似度最大,把相似度最大的那个 Vector 拿出来,输到decoder里面。
如果把整个 Process用 Self-attention 来比喻的话,那就等于是 Key 跟 Value 是共同的 Vector,然后把这个 Vector 输入 Decoder中,然后要它输出一张图片, Training 的时候,要让输入跟输出越接近越好。
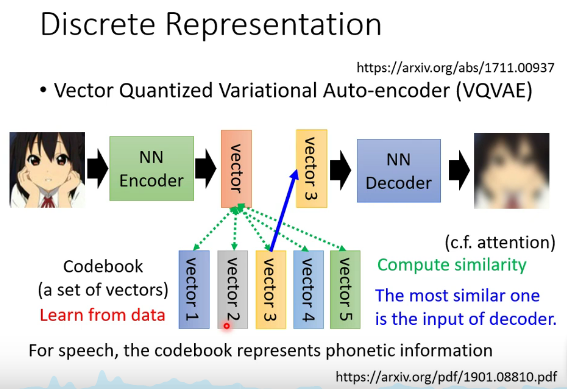
Encoder、Decoder以及 Codebook都是从数据中学出来的,这样做的好处是可以有 Discrete Latent Representation。
也就是 Decoder 的输入一定是 Codebook中向量的其中一个。假设 Codebook 中有 32 个向量, Decoder 的输入就只有 32 种可能,就是这个 Embedding是离散的,没有无穷无尽的可能,它只有 32 种可能。
举例来说,如果一段声音讯号输进来,经过这样的训练后,可能可以发现这个 Codebook 可以学到最基本的发音部位。
Text as Representation
Embedding也可以就是一串文字。
如果把 Embedding 变成一串文字,也许这串文字就是文章的摘要。把一篇文章输入 Encoder。输出一串文字,然后可以利用这段文字,通过 Decoder 还原回原来的文章。说明这段文字是这篇文章的精华,也就是这篇文章最关键的内容,也就是这篇文章的摘要。
不过这不是一个普通的 Auto-Encoder而是一个 seq2seq2seq 的 Auto-Encoder。它把长的 Sequence 转成短的 Sequence,再把短的 Sequence 还原回长的 Sequence。

但实验表明这样直接Train 是行不通的。因为这两个 Encoder 跟 Decoder 之间会发明自己的暗号,所以它会产生一段文字,是你看不懂的,但 Decoder 可以看得懂,它可以还原原来的文章。但是人看不懂所以它根本就不是一段摘要,就像之前可视化数字分类最后一层的embedding,只是机器能看懂。

可以再用 GAN 的概念,加上一个 Discriminator,来限制生成的句子,让人能看得懂。Discriminator 看过人写的句子,所以它知道人写的句子长什么样,但训练Discriminator 的这些句子不需要是这些文章的摘要,只需要是大量的人写的文本就可以。
然后 Encoder 要想办法产生一段句子,这段句子不止可以通过 Decoder还原回原来的文章,还要去骗过 Discriminator,让 Discriminator 觉得像是人写的句子,然后可以强迫 Encoder不只产生一段密码可以给 Decoder 去破解。而是产生一段人看得懂的摘要。

这种很复杂的训练可以用强化学习(reinforce learning)去做。
下图是实际上做的结果,给它读一篇文章,然后它就用 Auto-Encoder 的方法,拿 300 万篇文章做训练,之后给它一篇新的文章,看 Encoder 输出的句子可以是人看得懂的摘要了。

还有拿 Tree Structure当做 Embedding,将一段文字把它变成 Tree Structure,再用 Tree Structure 还原一段文字:

其他应用
把 Decoder 拿出来其实就是一个 Generator (输入一个向量,产生一个东西)。比如可以用输入Decoder 一个向量,产生一张图片。所以可以把Decoder当做一个 Generator 来使用。

于是可以从一个已知的 Distribution中,比如说 Gaussian Distribution,Sample 一个向量输入给 Decoder,看看它能不能够输出一张图。
VAE,Variarional Auto-Encoder(变分自动编码器)就是把 Auto-Encoder 的 Decoder 拿出来当做 Generator 使用,通过对编码器添加约束,强迫它产生服从单位高斯分布的潜在变量。之后就只要从单位高斯分布中进行采样,然后把它传给解码器就可以生成图片了。
Compression压缩
Auto-Encoder 还可以拿来做压缩。Encoder 压缩, Decoder 解压缩。只是这个压缩是lossy 的压缩,也就是它会失真。因为在 Train Auto-Encoder 的时候,没有办法 Train 输入的图片跟输出的图片100% 完全一模一样,还是会有一些差距。

Anomaly Detection异常检测
异常检测做的事情就是:输入一批新的数据,它到底跟之前在训练资料里面看过的资料相不相似。
- 如果看起来像是训练资料里面的 Data,就说它是正常的;
- 如果看起来不像是训练资料里面的 Data,就说它是异常的。
异常点也叫Outlier、Novelty、Exceptions等等。但是相似这件事并没有非常明确的定义,会根据应用情境而有所不同。某个数据是正常或异常,取决于训练资料长什么样子。

异常检测的应用

- 诈欺侦测,假设有一大堆信用卡的交易纪录,多数信用卡的交易都是正常的,拿这些正常的信用卡训练的交易纪录来训练一个异常检测的模型,当一笔新的交易纪录进来,可以让机器判断这笔纪录算是正常的 还是异常的;
- 网络侵入侦测:收集到一大堆正常的网络访问的连接纪录,接下来有一笔新的连接进来,可以根据过去正常的连线,训练出一个异常检测的模型,看看新的连线是正常的连线还是异常的连线;
- 医学:收集一大堆正常细胞的资料,训练一个异常检测的模型,看到一个新的细胞可以知道这个细胞有没有突变;
异常检测和二元分类的区别
二元分类需要负样本的标记;而在异常检测中往往只能得到大量的正样本标记,不容易收集到异常样本的数据。
比如诈欺侦测中,可能有一大堆信用卡交易的纪录,但是多数信用卡交易的纪录可能都是正常的,异常的资料相较于正常的资料可能非常地少。甚至有一些异常的资料混在正常的里面,也完全没有办法侦测出来。

所以它不是一个一般的分类的问题,这种分类的问题又叫做 One Class 的分类问题,就是我们只有一个类别的资料,这个时候 Auto-Encoder就可以派得上用场。
怎么检测呢?
比如说现在需要做一个图片检测的系统,可以拿多张图片训练一个 Auto-Encoder,然后当输入一张图片,看decoder重建以后的图片是不是和原图差异很大,如果差异很小 Decoder 可以顺利地还原原来的照片,代表这样类型的照片,是在训练的时候有看过的;反过来说,假设有一张照片是训练的时候没有看过的,差异就会很大,也就可能是异常的。


More about Anomaly Detection
异常检测不是只能用 Auto-Encoder 这个技术,李宏毅老师有关异常检测更完整的课程如下:
•Part 1: https://youtu.be/gDp2LXGnVLQ
•Part 2: https://youtu.be/cYrNjLxkoXs
•Part 3: https://youtu.be/ueDlm2FkCnw
•Part 4: https://youtu.be/XwkHOUPbc0Q
•Part 5: https://youtu.be/Fh1xFBktRLQ
•Part 6: https://youtu.be/LmFWzmn2rFY
•Part 7: https://youtu.be/6W8FqUGYyDo
