《统计学习方法》阅读笔记——第3章-k近邻法
统计学习方法笔记——第3章-k近邻法
k 近邻法(k-nearest neighbor,k-NN)是一种基本分类与回归方法。《统计学习方法》一书中讨论分类问题中的 k 近邻法。
k 近邻算法
用k 近邻法分类时,对新的实例,根据给定的距离度量,找出其 k 个最近邻的训练实例,根据最邻近 k 个实例的类别,通过多数表决等方式对该实例的类别进行预测(这 k 个实例的多数属于某个类,就把该输入实例分为这个类)。
有以下特点:
- k 近邻法不具有显式的学习过程。
- k 近邻法实际上利用训练数据集对特征向量空间进行划分,并作为其分类的“模型”。
- k值的选择、距离度量及分类决策规则是k 近邻法的三个基本要素。当训练集、距离度量、 k 值及分类决策规则确定后,k临近法的结果唯一确定。
特别的,当$ k=1\(时,称为**最近邻算法**:对于输入的实例点(特征向量)\) x$ ,最近邻法将训练数据集中与$ x \(最邻近点的类作为\) x$ 的类。
k 近邻模型
模型
k 近邻法使用的模型实际上是对特征空间的划分。
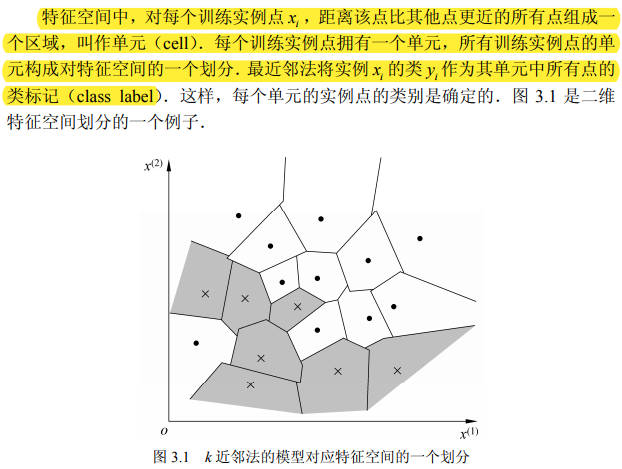
模型由三个基本要素:距离度量、 k 值的选择和分类决策规则决定。
距离度量
距离度量特征空间两个实例点的相似程度。
关于距离度量可以参考之前的笔记:距离计算
由不同的距离度量所确定的最近邻点是不同的。
k 值的选择
k 值的选择会对 k 近邻法的结果产生重大影响。
- 选择较小的 k 值:
- 相当于用较小的邻域中的训练实例进行预测;
- “学习”的近似误差(approximation error)会减小,只有与输入实例较近的(相似的)训练实例才会对预测结果起作用;
- 缺点是“学习”的估计误差(estimation error)会增大,预测结果会对近邻的实例点非常敏感。如果邻近的实例点恰巧是噪声,预测就会出错;
- k 值的减小就意味着整体模型变得复杂,容易发生过拟合。
- 选择较大的 k 值:
- 相当于用较大邻域中的训练实例进行预测;
- 其优点是可以减少学习的估计误差;
- 缺点是学习的近似误差会增大,这时与输入实例较远的(不相似的)训练实例也会对预测起作用,使预测发生错误;
- k 值的增大就意味着整体的模型变得简单(当k=N时,无论输入实例是什么都预测其属于训练实例中最多的类)。
在应用中,k 值一般取一个比较小的数值。通常采用交叉验证法来选取最优的 k 值。
分类决策规则
k 近邻法中的分类决策规则往往是多数表决,即由输入实例的 k 个邻近的训练实例中的多数类决定输入实例的类。
多数表决规则等价于经验风险最小化,证明如下:
经验风险最小化->误分类率最小:误分类概率为:\(P(Y\neq f(x))=1-P(Y=f(x))\)。
对于给定的实例 \(x\in \mathcal X\),其最近邻的 \(k\) 个训练实例点构成集合\(N_k(x)\) .如果涵盖\(N_k(x)\)的区域的类别是\(c_j\),那么误分类率是: \[ \frac{1}{k}\sum_{x_i \in N_k(x)}I(y_i\neq c_j)=1-\frac{1}{k}\sum_{x_i \in N_k(x)}I(y_i= c_j) \] 于是要最大化\(\sum_{x_i \in N_k(x)}I(y_i= c_j)\),等同于多数表决规则。
k 近邻法的实现:kd 树
实现 k 近邻法时,搜索k近邻的最简单的实现方法是线性扫描(linear scan),计算输入实例与每一个训练实例的距离。当训练集很大时,计算非常耗时,这种方法是不可行的。
kd 树是二叉树,利用一种特殊的结构存储训练数据,以减少计算距离的次数,从而对训练数据进行快速 k 近邻搜索。
构造kd树
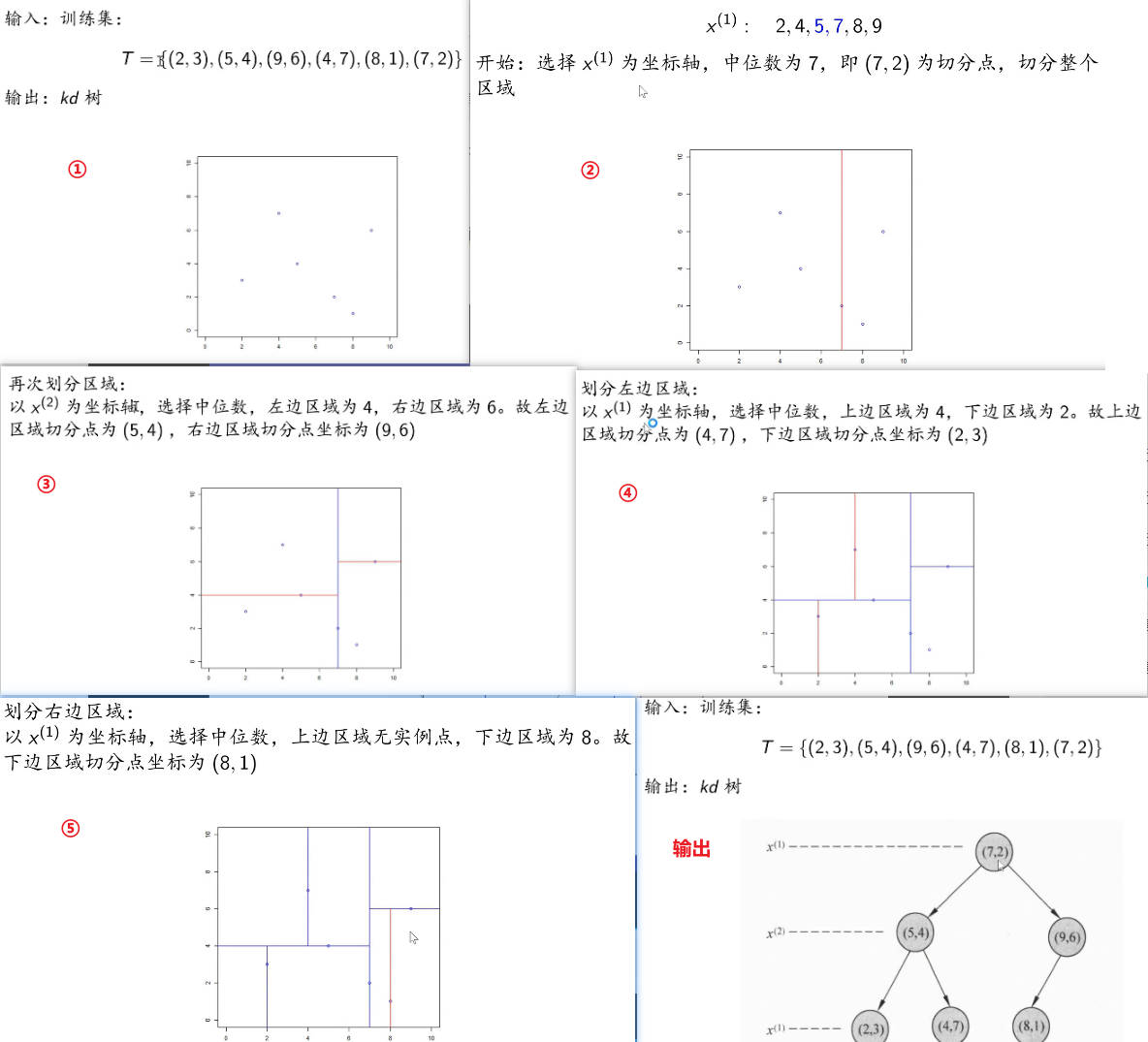
kd 树是二叉树,表示对k 维空间(注意此处的k与k近邻法的k意义不同)的一个划分(partition)。不断地用垂直于坐标轴的超平面将k 维空间切分,构成一系列的k 维超矩形区域,从而构建kd树。kd 树的每个结点对应于一个 k 维超矩形区域。
构造kd树算法

构造kd树案例
搜索kd树
如果实例点是随机分布的,kd 树搜索的平均计算复杂度是\(O (\log N)\) , \(N\)是训练实例数。
kd 树更适用于训练实例数远大于空间维数(\(N>>k\))时的 k 近邻搜索。当空间维数接近训练实例数时,它的效率会迅速下降,几乎接近线性扫描。
用kd树的最邻近搜索

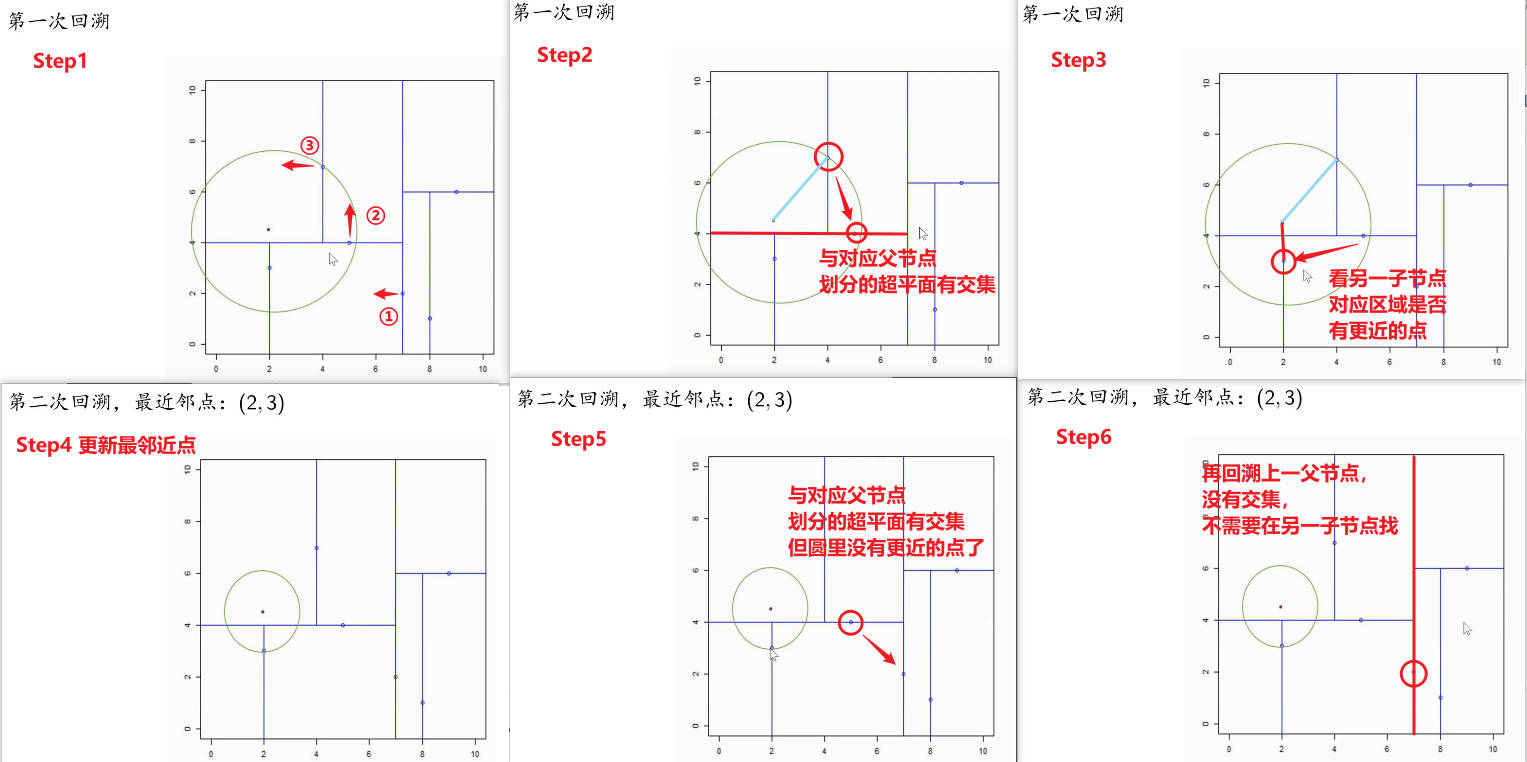
最近邻搜索案例(kd树)
以前面构造的kd树为例,对点\((2,4.5)\)的最近邻搜索过程。
习题
习题3.1
题目
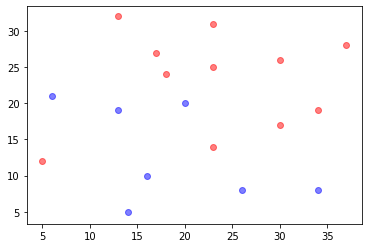
参照图 3.1,在二维空间中给出实例点,画出k 为 1 和 2 时的k 近邻法构成的空间划分,并对其进行比较,体会k 值选择与模型复杂度及预测准确率的关系。
解
训练集
import numpy as np |
创建并训练模型
利用sklearn.neighbors.KNeighborsClassifier,分别设置k=1和k=2,得到两个k近邻分类器,默认为欧氏距离,参数设置可参考sklearn.neighbors.KNeighborsClassifier()函数解析(最清晰的解释)_种树最好的时间是10年前,其次是现在!!!-CSDN博客:
from matplotlib.colors import ListedColormap |
可视化结果
# 设置图形标题 |
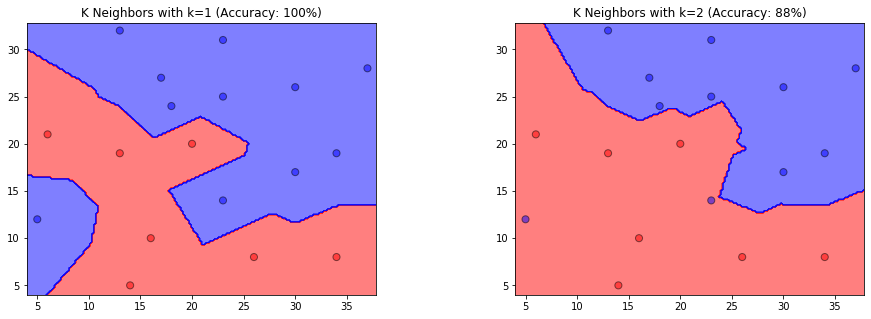
分析结果
- 当\(k=1\)时,训练集的分类精度为100%,当\(k=2\)时,训练集的分类精度为88%。
- k 值过小整体模型变得复杂,容易发生过拟合。
习题3.2
题目
利用例题 3.2 构造的 kd 树求点 \(x =(3,4.5)^T\) 的最近邻点。
解
方法1:图解
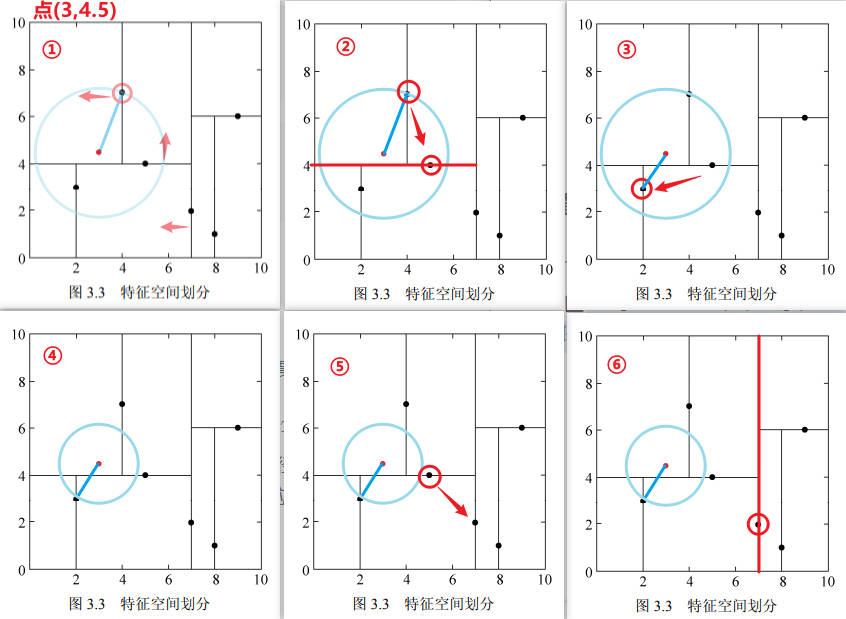
根据以上图解可知, \(x =(3,4.5)^T\) 的最近邻点是\((2,3)^T\)。
方法2:sklearn代码解
import numpy as np |
习题3.3
题目
参照算法 3.3,写出输出为 \(x\) 的 k 近邻的算法
解
算法回顾(算法3.3)
输入:已构造的kd树;目标点\(x\); 输出:\(x\)的k近邻
- 在kd树中找出包含目标点\(x\)的叶结点:从根结点出发,递归地向下访问树。若目标点\(x\)当前维的坐标小于切分点的坐标,则移动到左子结点,否则移动到右子结点,直到子结点为叶结点为止;
- 如果“当前k近邻点集”元素数量小于k或者叶节点距离小于“当前k近邻点集”中最远点距离,那么将叶节点插入“当前k近邻点集”;
- 递归地向上回退,在每个结点进行以下操作:
- 如果“当前k近邻点集”元素数量小于k或者当前节点距离小于“当前k近邻点集”中最远点距离,那么将该节点插入“当前k近邻点集”。
- 检查另一子结点对应的区域是否与以目标点为球心、以目标点与“当前k近邻点集”中最远点间的距离为半径的超球体相交。
- 如果相交,可能在另一个子结点对应的区域内存在距目标点更近的点,移动到另一个子结点,接着,递归地进行近邻搜索;
- 如果不相交,向上回退;
- 当回退到根结点时,搜索结束,最后的“当前k近邻点集”即为\(x\)的近邻点。
构造平衡kd树
方法1:
from sklearn.neighbors import KDTree |
方法2:
import json |
打印邻近节点
# 打印信息 |
查询k近邻
import numpy as np |
参考资料
DataWhale资料-第3章 k近邻法 (datawhalechina.github.io)
sklearn.neighbors.KNeighborsClassifier()函数解析(最清晰的解释)_种树最好的时间是10年前,其次是现在!!!-CSDN博客

