西瓜书阅读笔记——第1章-绪论
西瓜书阅读笔记——第1章-绪论
只记录和补充一些比较容易混淆、易忘、容易表述错误的内容。
基本概念
分类classification、回归regression、多分类multi-classification、聚类clustering
分类-预测离散值(有监督):西瓜是“好瓜”或“坏瓜”;树的类别是梧桐或三球悬铃木或银杏;
回归-预测连续值(有监督):西瓜成熟度0.95、0.37;树高1.4米、3.2米。
多标签分类(有监督):某个样本可以有多个标签,比如一棵树是银杏且是黄色,另外一棵树是三球悬铃木且是黄色。
聚类(无监督):学习过程中使用的训练样本不拥有标记信息。
训练training、验证validation/develop、测试testing
学得模型后,使用其进行预测的过程称为测试。
为什么要将数据集划分为三个部分?三个部分的作用?三个部分数据集的比例应如何设定?
另外一种常见的数据集划分方法是将数据集划分为两个部分(训练集和测试集),这种划分方法存在的问题在于,模型利用训练集数据进行训练,测试集数据进行模型泛化性测试。但我们不能利用测试集测试的bad case或者根据测试集的测试精度调整模型的参数。这是因为对于模型来说,数据集应该是只有训练集可见的,其他数据均不可见,如果利用测试集的结果调整模型相对于模型也”看到了“测试集的数据。将数据集划分为是独立同分布的三个部分就可以解决这个问题,将训练集数据用于模型训练,验证集(开发集)数据用于模型调参,测试集数据用于验证模型泛化性。
对于规模较小的数据集来说(10k及以下级别),训练集:验证集:测试集比例为6:2:2(划分两部分的话为7:3)较为合适,若数据集较大(如百万级),常见的比例为98:1:1 ,或者99.5:0.3:0.2等。
泛化generalization
学得模型适用于新样本的能力。训练集通常只是样本空间的一个很小的采样,希望用训练集训练出的模型能很好地反映出整个样本空间的特性。
归纳induction和演绎deduction
归纳:从特殊到一般的“泛化”过程,从具体事实归结一般规律。
演绎:从一般到特殊的“特化”过程,从基础原理推演具体情况。
假设hypothesis、版本空间hypothesis space
假设:模型属于由输入空间到输出空间的映射的集合,这个集合就是假设空间(hypothesis space)。(说人话简单点应该就是样本所有可能的取值。
版本空间:可能有多个假设与训练集一致,即存在着一个与训练集一致的"假设集合"(version space).
归纳偏好inductive、奥卡姆剃刀原则Occam's razor
在学习过程中对某种类型假设的偏好。有效的机器学习算法必有其归纳偏好。基于某种领域的知识而产生的归纳偏好,与特征选择不同,特征选择是基于训练样本分析选择有效的特征或者更加重视某类特征。
归纳偏好与问题本身匹配,偏好什么能让模型更好。 "奥卡姆剃刀"(Occam's razor)是一种常用的、自然科学研究中最基本的原则,用于确立"正确的"偏好——即"若有多个假设与观察一致,则选最简单的那个“。
没有免费午餐定理No Free Lunch Theorem NFL
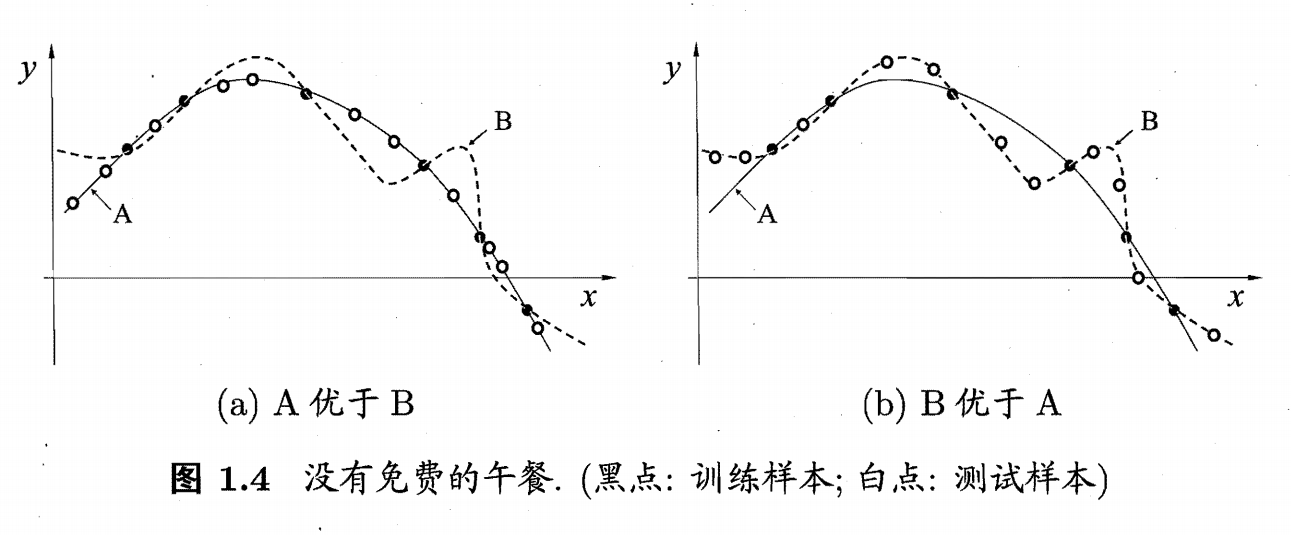
根据奥卡姆剃刀原则,下图(a)中A曲线的泛化能力要比曲线B强,但可能存在图(b)这样的情况,B曲线更好地满足测试集样本。也就是说,针对某种分布的样本空间(某种问题),算法A可能优于B,而针对另外一种分布的样本空间(另外一种问题),算法B可能优于A,这就引出了没有免费午餐定理。
没有免费午餐定理表明:若考虑所有潜在的问题,所有学习算法的误差期望相同,也就是所有算法都一样好。因此,脱离具体问题空谈什么学习算法更好没有意义,在某些问题上表现好的学习算法在另外一些问题上可能不尽人意。学习算法自身的归纳偏好与目标问题是否匹配往往起决定作用。
机器学习、云计算、众包crowdsourcing
大数据时代的三大关键技术:机器学习、云计算、众包
机器学习提供数据分析能力,云计算提供数据处理能力,众包提供数据标记能力。
