西瓜书阅读笔记——第3章-线性判别分析(3.4)
西瓜书阅读笔记——第3章-线性判别分析(3.4)
强烈推荐配合西瓜书阅读使用的南瓜书和南瓜书作者录制的学习视频【吃瓜教程】《机器学习公式详解》(南瓜书)与西瓜书公式推导直播合集。
线性判别分析(Linear Discriminant Analysis,LDA)
二分类LDA模型
原理
给定训练样法将样例投影到一条直线上,使得:
- 同类样例的投影点尽可能接近;
- 异类样例投影点尽可能能远离。
在对新样本进行分类时,将其投影到该直线上,再根据投点的位置来确定样本的类别。
如下图所示:
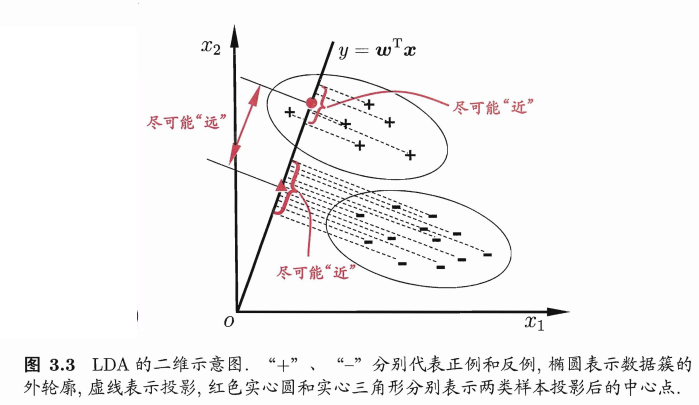
对应到机器学习三要素中分别为:
- 模型:\(f(\mathbf x)=\mathbf w^T\mathbf x\)。
- 策略:经投影的类内方差尽可能小;经投影的异类样本中心尽可能远。
- 算法:拉格朗日乘子法求解\(\mathbf w\)的最优闭式解。
策略——构建loss function
经投影的类内方差尽可能小
假设属于两类的试验样本数量分别是 \(m_0\)和 \(m_1\),经投影的类内方差\(Var_{C_0}\)可表示为: \[ \begin{align} Var_{C_0}=&\frac{1}{m_0}\sum\limits_{i=1}^{m_0}(y_i-\overline{y_{C_0}})(y_i-\overline{y_{C_0}})^T\nonumber \\=&\frac{1}{m_0}\sum\limits_{i=1}^{m_0}(w^Tx_i-\frac{1}{m_0}\sum\limits_{j=1}^{m_0}w^Tx_j)(w^Tx_i-\frac{1}{m_0}\sum\limits_{j=1}^{m_0}w^Tx_j)^T\nonumber \\=&w^T\frac{1}{m_0}\sum\limits_{i=1}^{N_1}(x_i-μ_0)(x_i-μ_0)^Tw\nonumber \\=&w^T\Sigma_0w \end{align} \] \(\mathbf \Sigma_0=\frac{1}{m_0}\sum\limits_{\mathbf x \in X_0}(\mathbf x-\mathbf μ_0)(\mathbf x-\mathbf μ_0)^T\)表示标记为类别0的原始数据的协方差,\(\mathbf μ_0\)为标记为类别0的原始数据的均值向量。
同理: \[ Var_{C_1}=w^T\Sigma_1w \] 则此”经投影的类内方差尽可能小“策略需要: \[ min( \mathbf w^T(\mathbf \Sigma_0+\mathbf \Sigma_1)\mathbf w) \]
经投影的异类样本中心尽可能远
用两类的均值表示经投影的异类样本中心,其距离平方为: \[ \begin{align} (\overline{y_{C_0}}-\overline{y_{C_1}})^2=&(\frac{1}{m_0}\sum\limits_{i=1}^{m_0}w^Tx_i-\frac{1}{m_1}\sum\limits_{i=1}^{m_1}w^Tx_i)^2\nonumber \\=&(w^T(μ_0-μ_1))^2\nonumber \\=&w^T(μ_0-μ_1)(μ_0-μ_1)^Tw \end{align} \] 则此”经投影的异类样本中心尽可能远“策略需要: \[ max(\bold w^T(\bold μ_0-\bold μ_1)(\bold μ_0-\bold μ_1)^T\bold w) \]
二分类线性判别的loss function
综合上述两点,由于协方差是一个矩阵,于是用将这两个值相除来得到损失函数\(J\),并最大化这个值: \[ \begin{align} \bold {\hat w}=&\mathop{argmax}\limits_{\bold w}J \\=&\mathop{argmax}\limits_{\bold w}\frac{(\overline{y_{C_0}}-\overline{y_{C_1}})^2}{Var_{C_0}+Var_{C_1}}\nonumber \\=&\mathop{argmax}\limits_{\bold w}\frac{\bold w^T(\bold μ_0-\bold μ_1)(\bold μ_0-\bold μ_1)^T\bold w}{\bold w^T(\bold \Sigma_0+\bold \Sigma_1)\bold w}\nonumber \\=&\mathop{argmax}\limits_{\bold w}\frac{\bold w^T\bold S_b\bold w}{\bold w^T\bold S_w\bold w} \end{align} \] 其中\(\mathbf S_b\)为类间散度矩阵(between-class scatter matrix),\(\mathbf S_w\)为类间散度矩阵(within-class scatter matrix)。\(J\)是\(\mathbf S_b\)和\(\mathbf S_w\)的广义瑞利商。
由于\(J\)的分子分母都是关于\(w\)的二次项,因此其解与\(w\)的长度无关(即使扩展或缩减了\(w\)的长度也可以被约分),只与方向有关。又因为给定训练集后,\(S_w\)为常量,因此可以将\(w\)进行缩放,令分母整体固定为一个常量,即:\(\mathbf w^T\mathbf S_w\mathbf w=1\)。
则可以进一步将loss function化为: \[ \mathop{argmin} \limits_\bold w -\bold w^T\bold S_b\bold w \\ s.t. \bold w^T\bold S_w\bold w=1 \]
算法——求解参数
拉格朗日乘子法(Lagrange multipliers)是一种寻找多元函数在一组约束下的极值的方法。通过引入拉格朗日乘子,可将有个\(d\)变量与\(k\)个约束条件的最优化问题转化为具有\(d+k\)个变量的无约束优化问题求解。


\(w\)是\(S_b\)相对于\(S_w\)的属于广义特征值\(λ\)的特征向量。
此时用拉格朗日乘子法求出来的极值点\(w\)一定是最小值点吗?

多分类LDA
全局散度矩阵
m为整个数据集的样本个数,\(S_t\)表示各个样本点到全部样本中心的距离和: \[ \mathbf S_t=\mathbf S_b+\mathbf S_w=\sum\limits_{i=1}^{m}(\mathbf x_i-\mathbf μ)(\mathbf x_i-\mathbf μ)^T \]
优化目标

其中\(\mathbf W=[\mathbf w_1;\mathbf w_2;...;\mathbf w_{N-1}]\),于是可拆分成: \[ \bold S_b\bold w_1=λ\bold S_w\bold w_1 \\ \bold S_b\bold w_2=λ\bold S_w\bold w_2 \\...... \\ \bold S_b\bold w_{N-1}=λ\bold S_w\bold w_{N-1} \] 即可得到\(N-1\)个\(λ\),\(λ_1≤λ_2≤...≤λ_{N-1}\)分别对应上面\(N-1\)个等式。
为什么W是N-1维?
新样本必须分到一个类中,那么如果都不属于其他类就只剩下最后一个类。
应用:分类、监督降维
若将\(\mathbf W\)视为一个投影矩阵,则多分类LDA将样本投影到\(N-1\)维空间,\(N-1\)通常远小子数据原有的属性数。可通过这个投影来减小样本点的维数,且投影过程中使用了类别信息,因此LDA也常被视为一种经典的监督降维技术。
附录
广义特征值
设\(A,B\)为\(n\)阶方阵,若存在数\(λ\),使得方程\(Ax=λBx\)存在非零解,则称\(λ\)为\(A\)相对于\(B\)的广义特征值,\(x\)为\(A\)相对于\(B\)的属于广义特征值\(λ\)的特征向量。特别地,当\(B=I\)(单位矩阵)时,广义特征值问题退化为标准特征值问题。
广义瑞丽商

参考文献
【吃瓜教程】《机器学习公式详解》(南瓜书)与西瓜书公式推导直播合集
*视频的PPT:https://pan.baidu.com/s/1g1IrzdMHqu6XyG0bFIcFsA 提取码: 7nmd
