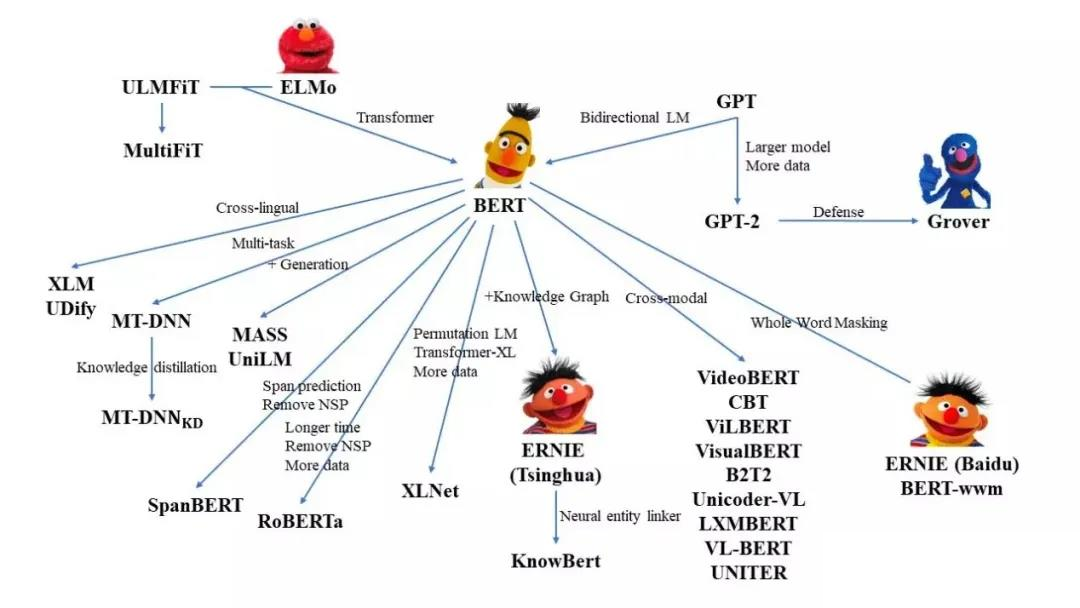
BERT实战——(7)生成任务-语言模型
BERT实战——(7)生成任务-语言模型
引言
之前的分别介绍了使用 🤗 Transformers代码库中的模型开展one-class任务(文本分类、多选问答问题)、class for each token任务(序列标注)、copy from input任务(抽取式问答)以及general sequence任务(机器翻译、摘要抽取)。
这一篇将介绍如何使用语言模型任务微调 🤗 Transformers模型(关于什么是语言模型,回看之前的博客-语言模型)。
任务介绍
我们这里主要完成两类语言建模任务:
- 因果语言模型(Causal language modeling,CLM):模型需要预测句子中的下一位置处的字符(类似BERT类模型的decoder和GPT,从左往右输入字符)。模型会使用矩阵对角线attention mask机制防止模型提前看到答案。例如,当模型试图预测句子中的\(i+1\)位置处的字符时,这个掩码将阻止它访问\(i\)位置之后的字符。
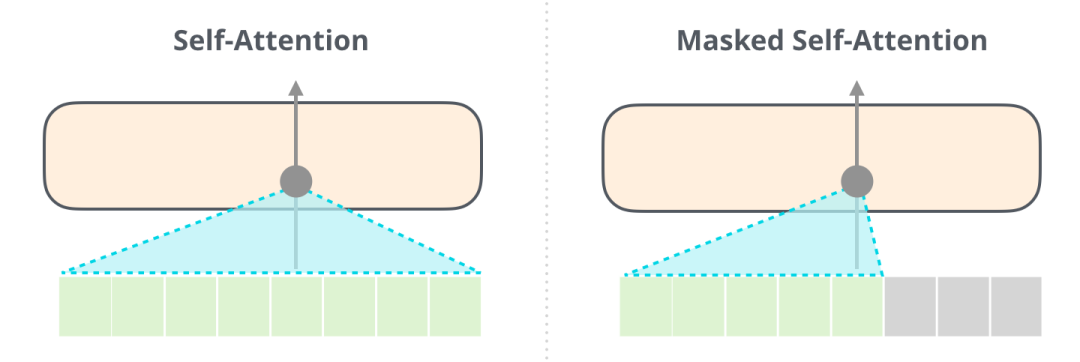
- 掩码语言建模(Masked language modeling,MLM):模型需要恢复输入中被"MASK"掉的一些字符(BERT类模型的预训练任务,只用transformer的encoder部分)。模型可以看到整个句子,因此模型可以根据“[MASK]”标记之前和之后的字符来预测该位置被“[MASK]”之前的字符。
主要分为以下几个部分:
- 数据加载;
- 数据预处理;
- 微调预训练模型:使用transformer中的
Seq2SeqTrainer接口对预训练模型进行微调(注意这里是Seq2SeqTrainer接口,之前的任务都是调用Trainer接口)。
前期准备
安装以下库:
pip install datasets transformers sacrebleu sentencepiece |
数据加载
数据集介绍
我们使用Wikitext 2数据集,其中包括了从Wikipedia上经过验证的Good和Featured文章集中提取的超过1亿个token的集合。
加载数据
该数据的加载方式在transformers库中进行了封装,我们可以通过以下语句进行数据加载:
from datasets import load_dataset |
如果碰到以下错误:
解决方案:
MAC用户: 在
/etc/hosts文件中添加一行199.232.68.133 raw.githubusercontent.comWindows用户: 在
C:\Windows\System32\drivers\etc\hosts文件中添加一行199.232.68.133 raw.githubusercontent.com

如果想加载自己的数据集可以参考之前的博客-定位词:加载自己的数据或来自网络的数据。
数据加载完毕后,给定一个数据切分的key(train、validation或者test)和下标即可查看数据。
datasets["train"][10] |
下面的函数将从数据集里随机选择几个例子进行展示,可以看到一些文本是维基百科文章的完整段落,而其他的只是标题或空行。
from datasets import ClassLabel |
show_random_elements(raw_datasets["train"]) |
| text | |
|---|---|
| 0 | MD 194D is the designation for an unnamed 0 @.@ 02 @-@ mile ( 0 @.@ 032 km ) connector between MD 194 and MD 853E , the old alignment that parallels the northbound direction of the modern highway south of Angell Road . |
| 1 | My sense , as though of hemlock I had drunk , |
| 2 | |
| 3 | A mimed stage show , Thunderbirds : F.A.B. , has toured internationally and popularised a staccato style of movement known colloquially as the " Thunderbirds walk " . The production has periodically been revived as Thunderbirds : F.A.B. – The Next Generation . |
因果语言模型(Causal Language Modeling,CLM)
数据预处理
在将数据喂入模型之前,我们需要对数据进行预处理。
仍然是两个数据预处理的基本流程:
- 分词;
- 转化成对应任务输入模型的格式;
Tokenizer用于上面两步数据预处理工作:Tokenizer首先对输入进行tokenize,然后将tokens转化为预模型中需要对应的token ID,再转化为模型需要的输入格式。
初始化Tokenizer
之前的博客已经介绍了一些Tokenizer的内容,并做了Tokenizer分词的示例,这里不再重复。use_fast=True指定使用fast版本的tokenizer。我们使用已经训练好的distilgpt2 模型checkpoint来做该任务。
from transformers import AutoTokenizer |
转化成对应任务输入模型的格式
对于因果语言模型(CLM),我们首先获取到数据集中的所有文本并分词,之后将它们连接起来。最后,在特定序列长度的例子中拆分它们,将各个拆分部分作为模型输入。
通过这种方式,模型将接收如下的连续文本块,[BOS_TOKEN]用于分割拼接了来自不同内容的文本。
输入类型1:文本1 |
调用分词器对所有的文本分词
def tokenize_function(examples): |
使用map函数对数据集datasets里面三个样本集合的所有样本进行预处理,将函数tokenize_function应用到(map)所有样本上。使用batch=True和4个进程来加速预处理。这是为了充分利用前面加载fast_tokenizer的优势,它将使用多线程并发地处理批中的文本。之后我们并不需要text列,所以将其舍弃(remove_columns)。
tokenized_datasets = datasets.map(tokenize_function, batched=True, num_proc=4, remove_columns=["text"]) |
我们现在查看数据集的一个元素,训练集中text已经被模型所需的input_ids所取代:
tokenized_datasets["train"][1] |
拼接文本&按定长拆分文本
我们需要将所有文本连接在一起,然后将结果分割成特定block_size的小块。block_size设置为预训练模型时所使用的最大长度。
编写预处理函数来对文本进行组合和拆分:
# block_size = tokenizer.model_max_length |
注意:因为我们做的是因果语言模型,其预测label就是其输入的input_id,所以我们复制了标签的输入。
我们将再次使用map方法,batched=True表示允许通过返回不同数量的样本来改变数据集中的样本数量,这样可以从一批示例中创建新的示例。
注意,在默认情况下,map方法将发送一批1,000个示例,由预处理函数处理。可以通过传递不同batch_size来调整。也可以使用num_proc来加速预处理。
lm_datasets = tokenized_datasets.map( |
检查一下数据集是否发生了变化:
tokenizer.decode(lm_datasets["train"][1]["input_ids"]) |
现在样本包含了block_size大小的连续字符块,可能跨越了几个原始文本。
' game and follows the " Nameless ", a penal military unit serving the nation of Gallia during the Second Europan War who perform secret black operations and are pitted against the Imperial unit " Calamaty Raven ". The game began development in 2010, carrying over a large portion of the work done on Valkyria Chronicles II. While it retained the standard features of the series, it also underwent multiple adjustments, such as making the game more forgiving for series newcomers. Character designer Raita Honjou and composer Hitoshi Sakimoto both returned from previous entries, along with Valkyria Chronicles II director Takeshi Oz'
微调预训练模型
数据已经准备好了,我们需要下载并加载预训练模型,然后微调预训练模型。
加载预训练模型
做因果语言模型任务,那么需要一个能解决这个任务的模型类。我们使用AutoModelForCausalLM 这个类。
和之前几篇博客提到的加载方式相同不再赘述。
from transformers import AutoModelForCausalLM |
设定训练参数
为了能够得到一个Trainer训练工具,我们还需要训练的设定/参数 TrainingArguments。这个训练设定包含了能够定义训练过程的所有属性。
from transformers import TrainingArguments |
定义评估方法
完成该任务不需要特别定义评估指标处理函数,模型将直接计算困惑度perplexity作为评估指标。
开始训练
将数据/模型/参数传入Trainer即可:
from transformers import Trainer |
调用train方法开始训练:
trainer.train() |
评估模型
一旦训练完成,我们就可以评估模型,得到它在验证集上的perplexity,如下所示:
import math |
掩码语言模型(Mask Language Modeling,MLM)
掩码语言模型相比因果语言模型好训练得多,因为只需要对mask的token(比如只占总数的15%)进行预测,同时可以访问其余的token。对于模型来说,这是一项更容易的任务。
数据预处理
和前面的步骤相同:
- 分词;
- 转化成对应任务输入模型的格式;
初始化Tokenizer
我们使用已经训练好的distilroberta-base模型checkpoint来做该任务。
from transformers import AutoTokenizer |
转化成对应任务输入模型的格式
对于掩码语言模型(MLM),我们首先获取到数据集中的所有文本并分词,之后将它们连接起来,接着在特定序列长度的例子中拆分它们。与因果语言模型不同的是,我们在拆分后还需要随机"MASK"一些字符(使用"[MASK]"进行替换)以及调整标签为只包含在"[MASK]"位置处的标签(因为我们不需要预测没有被"MASK"的字符),最后将各个经掩码的拆分部分作为模型输入。
调用分词器对所有的文本分词
应用一个和前面相同的分词器函数,只需要更新分词器来使用刚刚选择的checkpoint:
def tokenize_function(examples): |
同样使用map函数对数据集datasets里面三个样本集合的所有样本进行预处理,将函数tokenize_function应用到(map)所有样本上。
tokenized_datasets = datasets.map(tokenize_function, batched=True, num_proc=4, remove_columns=["text"]) |
拼接文本&按定长拆分文本
我们需要将所有文本连接在一起,然后将结果分割成特定block_size的小块。block_size设置为预训练模型时所使用的最大长度。
编写预处理函数来对文本进行组合和拆分:
# block_size = tokenizer.model_max_length |
注意:我们这里仍然复制了标签的输入作为label,因为掩码语言模型的本质还是预测原文,而掩码在data collator中通过添加特别的参数进行处理,下文会着重说明。
我们将再次使用map方法,batched=True表示允许通过返回不同数量的样本来改变数据集中的样本数量,这样可以从一批示例中创建新的示例。
注意,在默认情况下,map方法将发送一批1,000个示例,由预处理函数处理。可以通过传递不同batch_size来调整。也可以使用num_proc来加速预处理。
lm_datasets = tokenized_datasets.map( |
微调预训练模型
数据已经准备好了,我们需要下载并加载预训练模型,然后微调预训练模型。
加载预训练模型
做掩码语言模型任务,那么需要一个能解决这个任务的模型类。我们使用AutoModelForMaskedLM 这个类。
和之前几篇博客提到的加载方式相同不再赘述。
from transformers import AutoModelForMaskedLM |
设定训练参数
为了能够得到一个Trainer训练工具,我们还需要训练的设定/参数 TrainingArguments。这个训练设定包含了能够定义训练过程的所有属性。
from transformers import TrainingArguments |
数据收集器data collator
data_collator是一个函数,负责获取样本并将它们批处理成张量。data_collator负责获取样本并将它们批处理成张量。掩码语言模型任务需要使用一个特殊的data_collator,用于随机"MASK"句子中的token。
注意:我们可以将MASK作为预处理步骤(tokenizer)进行处理,但tokenizer在每个阶段字符总是以相同的方式被掩盖。而通过在data_collator中执行这一步,可以确保每次生成数据时都以新的方式完成掩码(随机)。
为了实现随机mask,Transformers为掩码语言模型提供了一个特殊的DataCollatorForLanguageModeling。可以通过mlm_probability调整掩码的概率:
from transformers import DataCollatorForLanguageModeling |
定义评估方法
完成该任务不需要特别定义评估指标处理函数,模型将直接计算困惑度perplexity作为评估指标。
开始训练
将数据/模型/参数传入Trainer即可:
from transformers import Trainer |
调用train方法开始训练:
trainer.train() |
评估模型
训练完成后就可以评估模型,得到它在验证集上的perplexity,如下所示:
import math |